最近写了一篇 RocketMQ 引入 RocksDB 的设计方案,在写这个的过程中我对 RocketMQ 的底层存储和架构更加清晰了,原本 RocketMQ 只停留在使用以及存储的应用层面,现在趁这个机会,好好的学习总结,周会上分享给大家!
全网仅有! 这个方案全网都没有什么参考资料,只能自己分析源码和学习并不完善的 RIP 66 : <https://github.com/apache/rocketmq/wiki/RIP-66-Support-KV(Rocksdb)-Storage >和 Apache 大会上阿里赵福建老师的简要介绍。
后续有可能会录个讲解视频放到这里!
那么,现在就开始吧!
前言
在分布式消息中间件领域,Apache RocketMQ 是一款备受欢迎的高性能、低延迟的消息队列系统,广泛应用于企业级消息通信、数据流处理和事件驱动架构中。而 RocksDB 则是一个高效的嵌入式键值数据库,其基于 LSM 树的存储设计,在随机写入和大规模数据管理方面表现出色。
近年来,随着企业消息队列的规模和复杂度迅速增长,传统的 RocketMQ 存储架构逐渐暴露出一些瓶颈。为应对这些挑战,社区引入了 RocksDB,作为一种新的存储方案,用于优化核心组件的性能和扩展能力。本文将重点讨论 RocketMQ 存储架构的现状及其局限性,并探讨 RocksDB 的引入是如何帮助解决这些问题的。
背景介绍
RocketMQ 存储结构
首先来回顾一下 ConsumeQueue 以及消息读写的过程。关于 RocketMQ 其他存储结构的介绍可以参考我的另一篇文档:RocketMQ 存储结构
ConsumeQueue
ConsumeQueue 引入的目的主要是提高消息消费的性能,由于 RocketMQ 是基于主题 topic 的订阅模式,消息消费是针对主题进行的。如果直接从 Commitlog 文件中根据 topic 检索消息是非常低效的,因此引入了 ConsumeQueue 作为“索引”,通过 ConsumeQueue,消费者可以直接定位到消息在 CommitLog 中的具体位置,从而快速完成消息消费。ConsumeQueue 的主要功能是存储以下三类索引信息:
消息的物理偏移量(offset): 指向 CommitLog 中对应消息的位置。
消息大小(size): 标识消息在 CommitLog 中的长度。
消息 Tag 的 HashCode: 便于快速匹配过滤消息。
ConsumeQueue 文件的默认大小为 6 MB,可存储约 30 万条消息的索引信息。
简单画个图: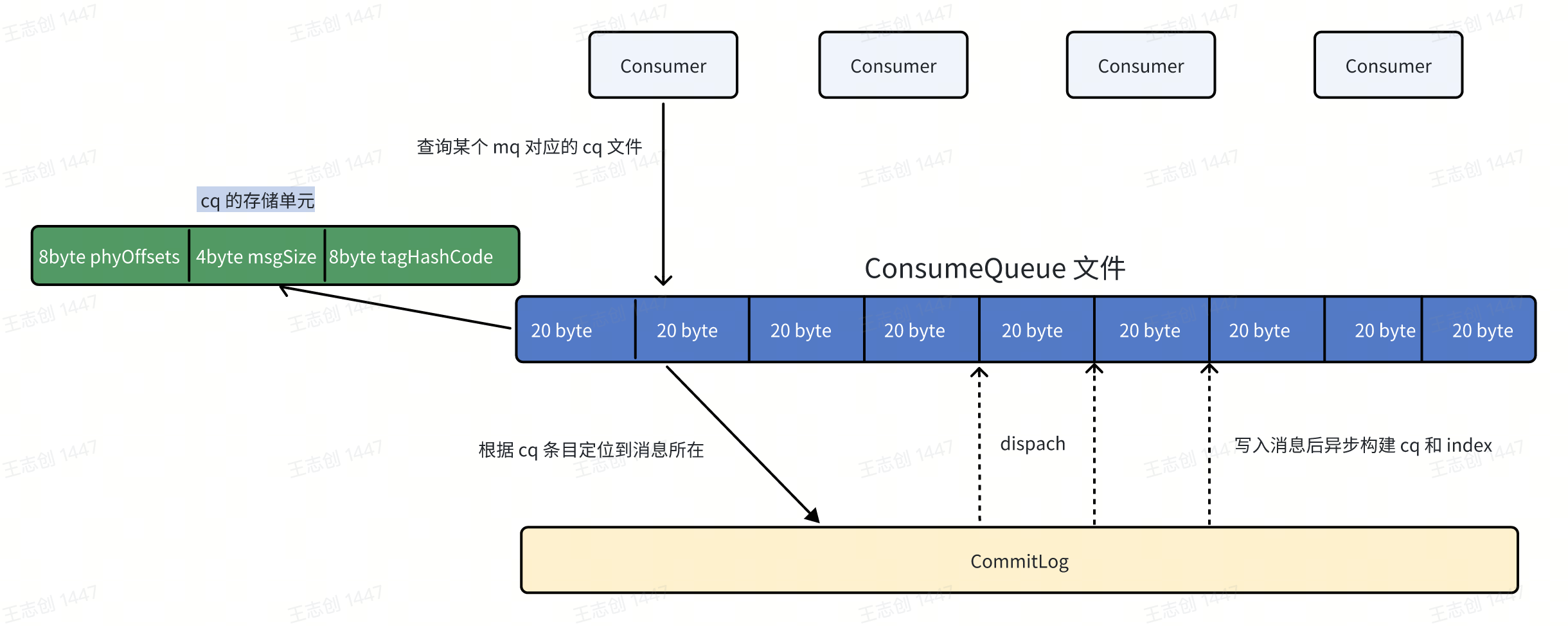
消息读写过程
消息读写的过程如下:
消息写入:
所有消息首先写入 CommitLog。
数据写入 CommitLog 后,
ReputMessageService(即 dispatch 线程)异步从 CommitLog 中读取消息数据,构建 ConsumeQueue 和 Index 文件,用于支持后续的消息消费和查询。Dispatch 线程提取消息的物理偏移量、消息长度及 Tag HashCode,将这些信息写入 ConsumeQueue,形成索引。
消息读取:
消费者通过逻辑偏移量从 ConsumeQueue 获取对应消息在 CommitLog 中的物理位置。
根据物理位置从 CommitLog 中读取原始消息,完成消费。
引用官方的一张图: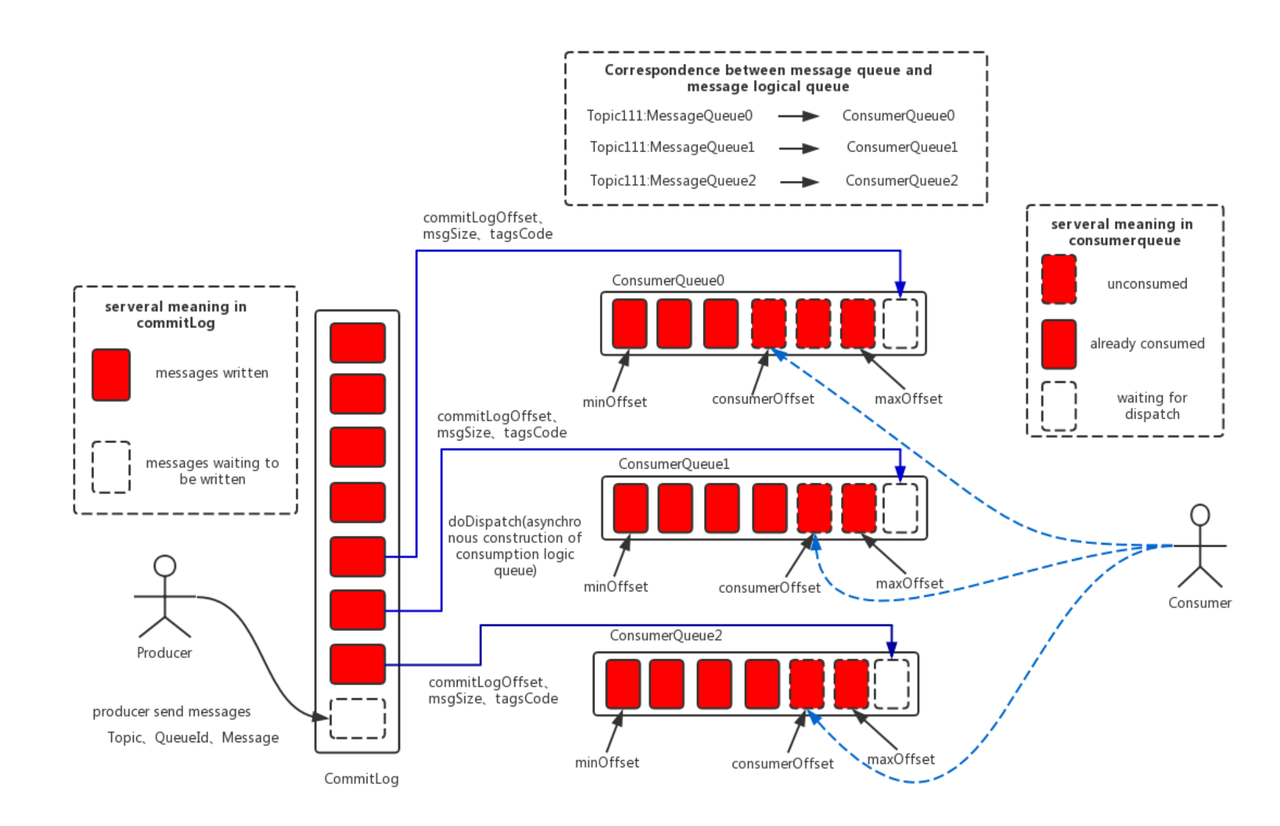
存储瓶颈
在一些生产环境中,随着消息队列规模的扩展,RocketMQ 的存储架构逐渐暴露出以下问题:
ConsumeQueue 文件管理成本高:
每个 Topic 的每个队列都对应一个 ConsumeQueue 文件。ConsumeQueue 索引是基于 mmap 实现的,在百万级 Topic 场景下,会产生数百万个小文件,这些小文件的随机写入破坏了 RocketMQ 一直依赖的 CommitLog 顺序写性能,随机读写瓶颈显现(文件内部顺序写,但是多文件是随机写)、性能急剧下降,极大地增加了文件系统的管理开销。
启动或重启时需要遍历所有文件,耗时长且容易引发 I/O 瓶颈。
LMQ 同样存在类似问题
LMQ 的轻量级设计能够支持亿级设备连接与百万级消息并发,满足物联网场景的需求。
虽然 LMQ 可以让一条消息对应多个索引,减少数据重复存储,但是同样会遇到队列文件过多带来的性能下降问题。
如何解决
为了优化百万级 Topic 场景下的存储性能和管理效率,RocketMQ 需要引入一种高效的存储引擎,来替代现有的 ConsumeQueue 文件管理机制。RocksDB 的设计完美契合这一需求: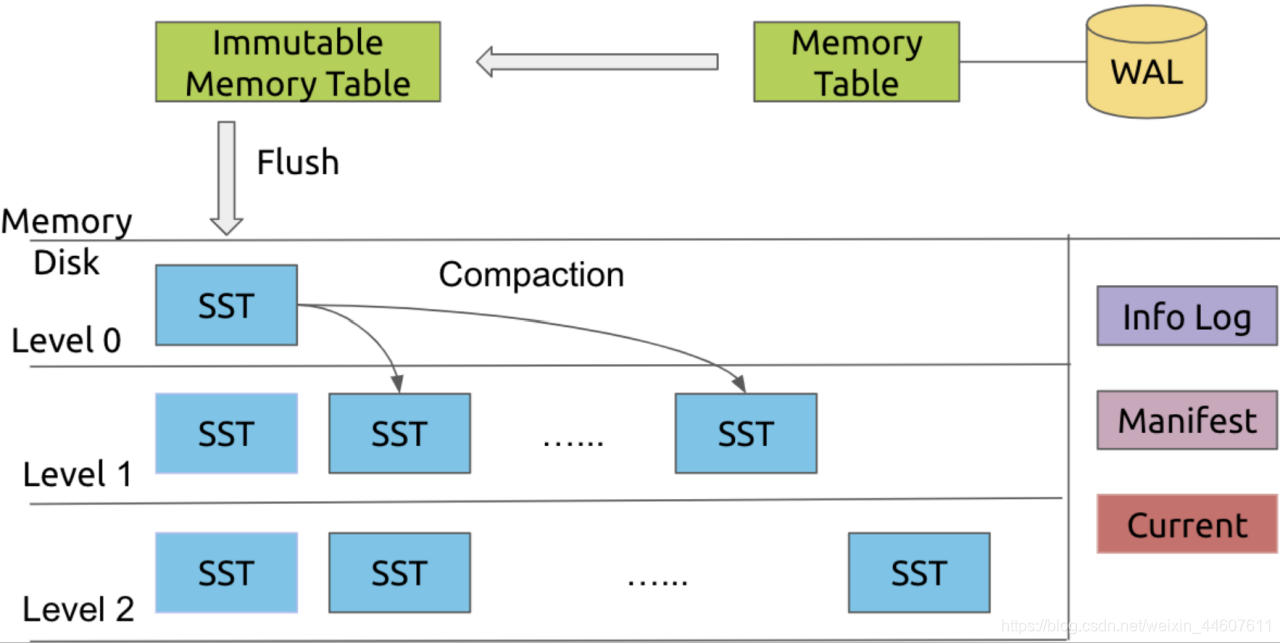
提升随机写性能:
RocksDB 基于 LSM 树(Log-Structured Merge Tree),通过 WAL(Write-Ahead Logging)和 MemoryTable 的机制,将随机写转化为 SST 文件的顺序写,显著提升写入性能。
RocksDB 的 Compaction 操作会将数据文件合并为 SST 文件并进行分层存储,进一步优化读写效率。
减少小文件管理开销:
RocksDB 将所有小文件条目聚合存储(变成内存 + SST 存储),大大减少了文件系统句柄的占用,避免 OOM 问题。
通过列族(Column Family)组织数据,可以灵活扩展和优化存储结构。
这里的列族实际上可以看作是一个表,里面存放了很多条数据记录。
优化启动性能
RocksDB 可以实现按需加载,在启动时候只需要加载必要的元数据信息,比如 Max 和 Min Offsets,不会把全部的 CQ 索引文件都加载到内存。
这种方式大幅减少了启动过程中的 I/O 操作和内存消耗,提升了系统的启动效率。
去除 RocksDB WAL
- CommitLog 存储了完整的 CQ 数据,并且真正的持久化成功了,因此 CQ 数据可以根据 CommitLog 进行重建。去除 WAL 可以进一步提升 RocksDB 写入性能。
扩展性强
RocksDB 作为嵌入式数据库,提供了列族(Column Family)特性,允许针对不同业务需求灵活调整存储设计。每个列族相当于一个独立的逻辑表,拥有独立的键空间和配置(如压缩策略、缓存策略等)。
列族可以用于隔离存储不同数据类型,例如 Topic 的消息索引、ConsumerOffset、DelayOffsets 等,实现更细粒度的管理和优化。
举一些例子:
高负载热点队列优化:
针对高负载或热点队列,分配独立的列族,并通过调整列族的写入缓存大小、压缩策略等手段进行单独优化。
对于低负载或非热点队列,可以共享列族,节省存储和内存资源。
这种设计确保热点队列不会因共享存储资源而影响性能,同时减少了整体的存储开销。
延迟队列优化:
RocketMQ 的延迟队列目前通过多个定时文件实现,存在大量小文件,管理复杂,且不同延迟级别的数据混合存储,难以灵活调整策略。
引入 RocksDB 后,可以按照延迟级别划分列族,将每个延迟级别的数据独立存储,并使用消息的延迟时间戳作为键。
这种设计既支持高效的按键查询,又方便延迟任务的范围查询,显著提升了性能和管理效率。
RocksDB 架构和核心特点
RocksDB 基础
RocksDB 是一种可持久化的、嵌入式的 kv 存储。
C++编写
基于 LevelDB,底层基于 LSM Tree
其实看到嵌入式的,可以很容易想到 SqLite 数据库,特别是在 RocksDB 的上下文中,“内嵌”意味着:
集成进应用,与应用共享内存,避免跨进程通信开销。
只支持本地存储,无法通过网络访问,也不提供分布式能力。
灵活高效,尤其适合高性能要求的小规模元数据存取。
支持的操作:
delete 删除键值对(逻辑删除,把记录类型改为 DEL,并把 value 置空)
put 增加或更新数据
merge 合并当前键值到已有的键值对
get (key)获取数据
支持迭代器遍历,比如根据某个以 prefix 为前缀的所有 key 之间的向前或向后迭代遍历
接下来我们聚集到数据读写上介绍 RocksDB。
写路径
RocksDB 的数据写入流程如下:
WAL (Write-Ahead Log) :
- 写操作会首先写入 WAL 日志,保证数据持久化(宕机恢复)。
MemTable:
数据同时写入内存中的 MemTable(默认基于 SkipList 实现)。
MemTable 支持并发写入,当写满时,转换为 Immutable MemTable 不可变的内存块。
刷盘 (Flush):
- Immutable MemTable 被后台线程刷盘,生成 SST 文件(Sorted String Table)存储到磁盘的 Level 0 层。
Compaction:
当 Level 0 的 SST 文件数量超过阈值时,触发 Compaction。
Compaction 会将上层的 SST 文件与下层 SST 文件合并且保证有序,丢弃无效数据(如被覆盖或删除的 Key)。
读路径
数据查询时主要是按照层级查找:
MemTable 和 Immutable MemTable:优先在内存中查找。
Level 0:遍历 L0 层所有 SST 文件。
Level 1 及以下:通过索引可以快速定位目标 SST 文件,再根据 SST 数据块查找 Key。
布隆过滤器(可选):快速排除不存在的数据,提升查询性能。
问题:为什么 L0 层要全部遍历?
L0 层的 SST 文件内部是有序的,但 L0 层的多个 SST 文件之间不一定有全局有序性,可能存在键的重叠,因为 Flush 操作将 Immutable MemTable 数据直接写入 L0 层生成新的 SST 文件,而不同 Flush 操作写入的 SST 文件之间没有进行合并,可能存在数据重叠(比如第一次 flush 操作 1, 5, 6。第二次 flush 操作 2, 8,块内有序,整体无序)。
由于 Compaction 的作用,L1 及以下的层,SST 文件不仅内部有序,不同 SST 文件之间也不会有键重叠,它们在逻辑上是全局有序的。
细节介绍
关于 RocksDB 更细节的介绍,这里不多介绍了。可以参考我的另一篇文档:RocksDB 优势
有趣的 merge
传统的合并操作的场景:对某个 key 的 value 上新增一部分数据(追加),我们的操作是 read -> append -> write。这种操作有一定缺陷:
可以看到这个操作实际上不是原子性的,即多线程同时更新会出现数据丢失。
写放大:如果写的数据比较大,或者数据量越来越大,之后的增量就都需要完整的把数据读出来再写入,浪费资源。
RocksDB 对这个做了优化:对于增量的数据先写入 MemoryTable 和 WAL****,等待 Compaction 和 Flush 操作到磁盘。如果这个期间(还没持久化到磁盘)有读请求,就在读的时候先检查有没有 hang 的 merge 操作,如果有那就先合并再返回合并后的数据给客户端。
这个问题也比较明显,每次读都需要合并数据,直到增量数据被持久化,不过这里也可以通过限制 MemTable 的容量等操作来让数据尽快的持久化。
RocksDB 在 RocketMQ 中的设计与实现
可行性分析
在前面的存储瓶颈与 RocksDB 介绍的基础上,为了实现在 RocketMQ 中对 CQ 相关数据的存储和读写,我们需要将原始的 CQ 存储单元(含 20 字节: phyOffsets,msgSize,tagCode),以及 min(或 max) offsets 通过 RocksDB 进行读写。因此,需要设计相关的列组(数据表),并保证可以根据 key 唯一确定到某条消息。
设计方案
我们分为以下三个层面进行:
架构层面
数据存储层面
代码层面
架构层面
这里主要描述如何构建 RocksDB CQ 单元和 Offset 的存储,以及消费关系,后续会在详细设计中介绍细节。
Tip: 此处仅描述 RocksDB 数据流。
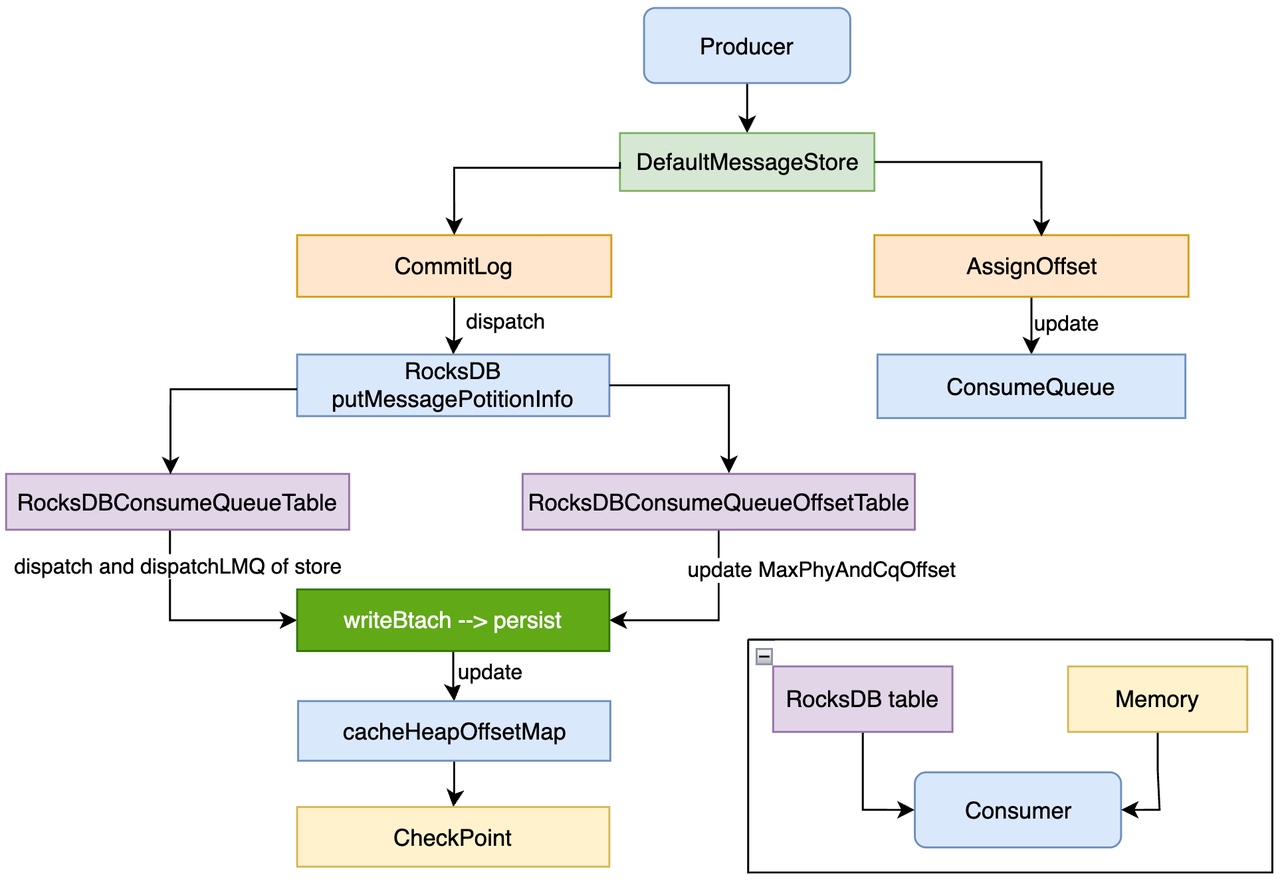
数据存储格式
在数据存储层面,我们需要考虑怎么唯一标识一条消息的索引。RocksDB 的 key 和 value 都是无结构的字节数组(byte[]),所以对于 key 和 value 的设置上是非常灵活的,这也意味着我们在新增、删除和更新数据的时候需要注意字节序列化和反序列化的处理。这里,我们将 CQ 相关的数据分为两个表:
- RocksDBConsumeQueueTable:存储物理 offset、tagCode、msgSize 等 CQ 相关字段,并额外增加时间戳扩展字段。
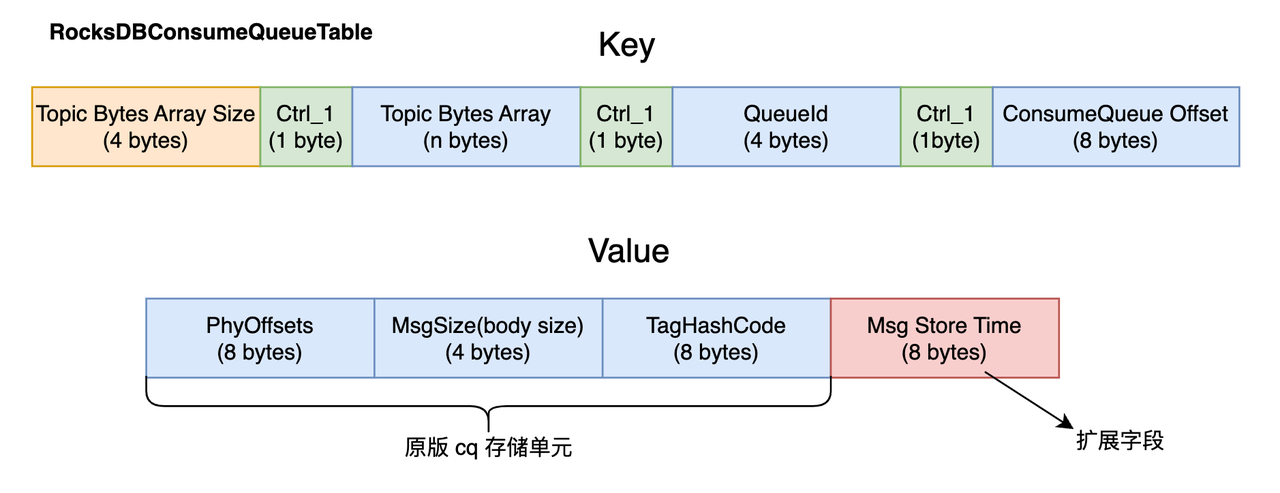
可以注意到:
由于 TopicName 的长度不固定,因此新增 Topic Bytes Array Size 字段用于确定 TopicName 的长度,这样在之后划分时更加方便。
Key 中新增了 Ctrl_1,即 ASCII 中的第一个字符,用于后续的删除操作。
Value 中新增了 Msg Store Time,主要是用于扩展的,即当查询某条消息的存储时间时,不需要按照之前那样拿到 phyOffsets 之后去 CommitLog 拿,这里直接存到 RocksDB 里可以避免一种问题: 冷数据消费或从某个时间点开始消费消息的场景,不会替换掉 pagecache 中的数据,能减少一定的抖动。(所以后续如果有什么类似的需求,我们也可以通过新增 KV 的字段来进行扩展)
- RocksDBQueueOffsetTable:存储线程对应的 Min 或 Max 逻辑 offset 和物理 offset:
我们得到最大偏移量和最小偏移量,传统的做法是进行全量扫描,拿到全部的 CQ 文件然后计算最小和最大偏移量。通过放到 RocksDB 中存储能更好的进行创建和维护,进一步提升性能。
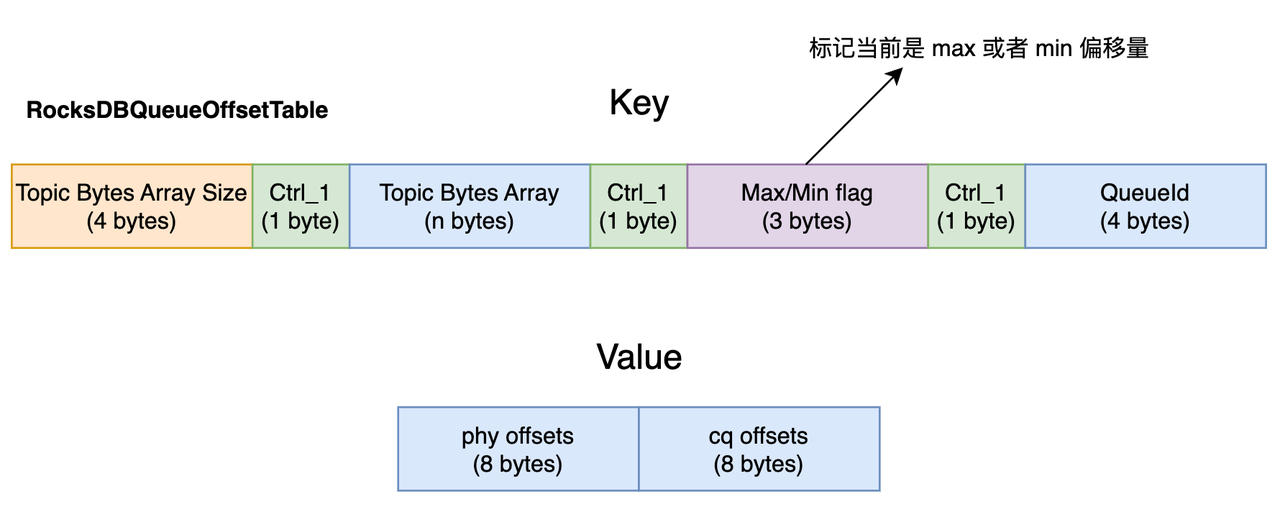
需要注意的一点是增加了 max/min 的标识,用于区分存储的是最大或最小偏移量。
代码层面
引入 ConsumeQueueStoreInterface 接口:定义 ConsumeQueue 的存储操作接口,便于不同存储实现的切换。
实现 RocksDBConsumeQueueStore:基于 RocksDB 实现了 ConsumeQueueStore 接口,负责消息消费队列的存储操作,比如获取最大/最小偏移量(逻辑或物理)。
引入抽象 AbstractConsumeQueueStore 类:实现 ConsumeQueueStoreInterface 接口,并提供 ConsumeQueue 的抽象实现,封装了通用逻辑,便于不同存储方式的具体实现。
实现 RocksDBConsumeQueue 类:实现 ConsumeQueueInterface,作为 RocksDBConsumeQueueStore 的操作单元,并调用其相关方法进行实际的数据读写操作。
修改 MessageStore 相关类:增加对 RocksDB 存储方式的支持。
配置调整:broker 初始化时根据配置决定存储方式,支持双写。
类图关系如下: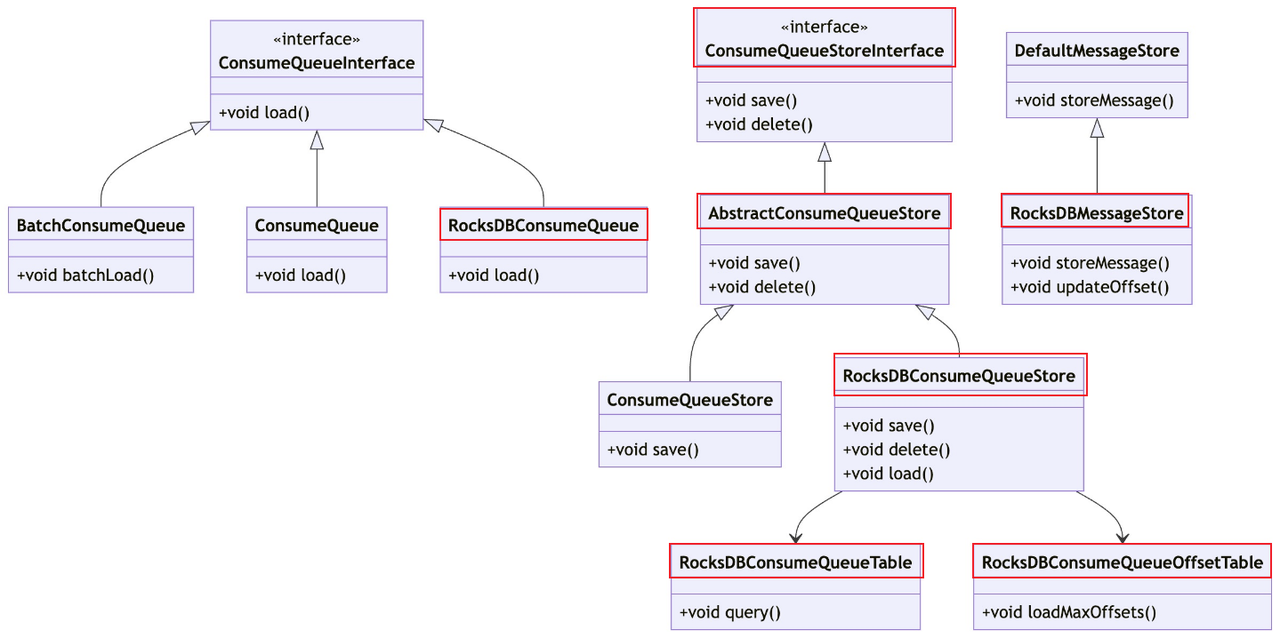
如何维护 CQ min offsets
如果 CommitLog 中的消息由于超过消息保留时间被删除,或者因为磁盘瓶颈被删除,那物理偏移量对应的消息可能就不存在了,我们需要维护 CQ 的最小偏移量来保证消费者不会读取到过期的消息
原版:采用的方式是增加一个定时任务去判断 CQ 的最小逻辑偏移量对应的物理偏移量是否失效了,如果失效就需要对 CQ 文件进行清理。
RocksDB 版本:不采用定时任务,当调用
getMinOffset的方式时判断是否过期,如果过期再删除并重新加载。
如何删除过期的 CQ 数据
原版:通过定时任务。
RocksDB 版本:实现 CompactionFilter,自定义过滤的方法,在 Compaction 过程中判断 CQ 数据是否过期(物理偏移量小于物理最小偏移量),如果过期则进行删除。
Topic 删除怎么处理表数据
RocksDB:Topic 删除后,需要删除 RocksDB 中对应的表数据,包括 CQ 表和 offset 表。RocksDB 是支持范围删除的,因此这里主要是通过拼接 Ctrl 标识来实现一个字典序差值的范围进行 CQ 文件的删除,具体的实现可以参考“详细实现”章节。
RocksDB 和 LMQ 支持同时开启
同样实现了基于 RocksDB 存储 LMQ 数据而并非使用文件系统,与一般 CQ 数据相比,主要区别在于 dispatch 以及维护逻辑偏移量的过程。后续会详细介绍。
兼容性考虑
无论 rocksdb 开关是开启还是关闭,原始的 RocketMQ 客户端和消息收发都不会受到影响。
统一实现了存储接口,原 MessageStore 等逻辑不变,如果开启 RocksDB 选项则走 RocksDB 的 Store 方式。并且支持原 MessageStore 模式下开启 RocksDB 双写选项,同时写入一份数据到 RocksDB 中,方便后续迁移。
详细实现
总共有 4800 行左右代码,这里介绍核心变更。
RocksDB 存储类实现
ConsumeQueueRocksDBStorage 类继承 AbstractRocksDBStorage ,主要实现数据启动时加载、数据的获取以及增删改、Flush 操作以及手动触发 Compaction 的方法。
Load 方法
当 RocketMQ 启动时会从磁盘中加载数据文件,以 ConsumeQueue 文件为例:
- 原版采用的方式是进行全量遍历:
在 BrokerController 中的初始化方法里调用 DefaultMessageStore 的 load 方法,其中加载 ConsumeQueue 的方法实现为:
遍历 CQ 目录下的所有 Topic 文件夹以及各分区下的 CQ 文件。
为每个 CQ 文件创建逻辑的 CQ 对象,包括 CQ 的类型以及对应的 topic 和 queueId。
根据逻辑的 CQ 对象,去 Consume 类中调用 mappedFileQueue 的 load 方法,从磁盘中加载数据。
private boolean loadConsumeQueues(String storePath, CQType cqType) {
File dirLogic = new File(storePath);
File[] fileTopicList = dirLogic.listFiles();
if (fileTopicList != null) {
for (File fileTopic : fileTopicList) {
String topic = fileTopic.getName();
File[] fileQueueIdList = fileTopic.listFiles();
if (fileQueueIdList != null) {
for (File fileQueueId : fileQueueIdList) {
int queueId;
try {
queueId = Integer.parseInt(fileQueueId.getName());
} catch (NumberFormatException e) {
continue;
}
queueTypeShouldBe(topic, cqType);
ConsumeQueueInterface logic = createConsumeQueueByType(cqType, topic, queueId, storePath);
this.putConsumeQueue(topic, queueId, logic);
if (!this.load(logic)) {
return false;
}
}
}
}
}
log.info("load {} all over, OK", cqType);
return true;
}- RocksDB 模式
RocksDB 模式下,并没有将 load 操作放到 RocksDBMessageStore 中,而是统一放到 RocksDBConsumeQueueStore 中,实现如下:
public boolean load() {
boolean result = this.rocksDBStorage.start();
this.rocksDBConsumeQueueTable.load();
this.rocksDBConsumeQueueOffsetTable.load();
log.info("load rocksdb consume queue {}.", result ? "OK" : "Failed");
return result;
}启动 RocksDB 存储类对象,其中调用了预加载方法 postLoad,主要是加载 CQ 单元表以及 Offset 表对应的列族和配置信息。(CQ 表为 default 列族, offset 表为 offset 列族)
分别通过相应的对象加载 RocksDB 中存储的 CQ 单元表以及 Offset 表。
对于 CQ 单元表,并没有将 CQ 数据直接全部加载到内存以及创建 CQ 逻辑对象,因为 CQ 数据量较大,将大量占用内存,降低启动时间,所以在需要查询时直接调用相关的接口查询即可。
对于 offset 表,由于 max/min 偏移量访问频率极高且计算过程需要进行全量扫描,因此在加载时放到内存中。
public void load() {
this.offsetCFH = this.rocksDBStorage.getOffsetCFHandle();
loadMaxConsumeQueueOffsets();
}
private void loadMaxConsumeQueueOffsets() {
// 过滤函数,仅保留代表最大偏移量的条目。
Function<OffsetEntry, Boolean> predicate = entry -> entry.type == OffsetEntryType.MAXIMUM;
// 定义了一个处理函数(fn),用于将筛选后的最大偏移量条目处理并存储到内存结构中。
Consumer<OffsetEntry> fn = entry -> {
topicQueueMaxCqOffset.putIfAbsent(entry.topic + "-" + entry.queueId, entry.offset);
log.info("Max {}:{} --> {}|{}", entry.topic, entry.queueId, entry.offset, entry.commitLogOffset);
};
try {
// 遍历 RocksDB offset 表对应的列族存储空间,并解析出 MaxOffsets。
forEach(predicate, fn);
} catch (RocksDBException e) {
log.error("Failed to maximum consume queue offset", e);
}
}
// 部分 forEach 方法内容:
public void forEach(Function<OffsetEntry, Boolean> predicate, Consumer<OffsetEntry> fn) throws RocksDBException {
// 获取该列族的迭代器,进行数据遍历。
try (RocksIterator iterator = this.rocksDBStorage.seekOffsetCF()) {
if (null == iterator) {
return;
}
// 忽略后续的字节操作以及调用处理函数。Recover 与 cleanDirty
RocksDB 模式下支持并发 recover,并实现脏数据的清理:
- RocksDBConsumeQueueStore 中调用 recover 或 recoverConcurrently 方法,这将直接调用当前类的 start 方法
@Override
public void recover() {
start();
}
@Override
public boolean recoverConcurrently() {
start();
return true;
}
@Override
public void start() {
if (serviceState.compareAndSet(ServiceState.CREATE_JUST, ServiceState.RUNNING)) {
log.info("RocksDB ConsumeQueueStore start!");
this.groupCommitService.start();
// 不管上一个任务是否执行完成都按照固定时间点执行
this.scheduledExecutorService.scheduleAtFixedRate(() -> {
this.rocksDBStorage.statRocksdb(log);
}, 10, this.messageStoreConfig.getStatRocksDBCQIntervalSec(), TimeUnit.SECONDS);
// 按照固定延迟执行任务,即上一个任务执行结束后固定延迟再执行
this.scheduledExecutorService.scheduleWithFixedDelay(() -> {
cleanDirty(messageStore.getTopicConfigs().keySet());
}, 10, this.messageStoreConfig.getCleanRocksDBDirtyCQIntervalMin(), TimeUnit.MINUTES);
}
}- start 方法中定义了两个定时任务,分别是 startRocksdb 以及 cleanDirty 方法。其中 startRocksDB 会重新 RocksDB 数据的重新加载,包括各个层的数据以及元数据列表。cleanDirty 方法则会进行 offset 表的无用 CQ 数据的清理(CQ 单元表会通过 Compaction 清理):
private void cleanDirty(final Set<String> existTopicSet) {
try {
// 遍历 offsetTable 寻找脏数据,实际上就是判断偏移量关系。
Map<String, Set<Integer>> topicQueueIdToBeDeletedMap =
this.rocksDBConsumeQueueOffsetTable.iterateOffsetTable2FindDirty(existTopicSet);
for (Map.Entry<String, Set<Integer>> entry : topicQueueIdToBeDeletedMap.entrySet()) {
String topic = entry.getKey();
for (int queueId : entry.getValue()) {
destroy(new RocksDBConsumeQueue(topic, queueId));
}
}
} catch (Exception e) {
log.error("cleanUnusedTopic Failed.", e);
}
}开启 RocksDB 存储配置
当 RocksDB 配置后,将作为一种新的功能注入到 broker,当 brokerController 调用初始化方法时,如果不配置 RocksDB 的存储,则走默认的 DefaultMessageStore,并且支持开启文件和 RocksDB 双写,方便后续迁移。
public boolean initialize() throws CloneNotSupportedException {
boolean result = this.topicConfigManager.load();
result = result && this.topicQueueMappingManager.load();
result = result && this.consumerOffsetManager.load();
result = result && this.subscriptionGroupManager.load();
result = result && this.consumerFilterManager.load();
if (result) {
try {
DefaultMessageStore defaultMessageStore;
if (this.messageStoreConfig.isEnableRocksDBStore()) {
defaultMessageStore = new RocksDBMessageStore(this.messageStoreConfig, this.brokerStatsManager,
this.messageArrivingListener, this.brokerConfig, topicConfigManager.getTopicConfigTable());
} else {
defaultMessageStore = new DefaultMessageStore(this.messageStoreConfig, this.brokerStatsManager,
this.messageArrivingListener, this.brokerConfig, topicConfigManager.getTopicConfigTable());
if (messageStoreConfig.isRocksdbCQDoubleWriteEnable()) {
defaultMessageStore.enableRocksdbCQWrite();
}
}
if (messageStoreConfig.isEnableDLegerCommitLog()) {
DLedgerRoleChangeHandler roleChangeHandler = new DLedgerRoleChangeHandler(this, defaultMessageStore);
((DLedgerCommitLog) defaultMessageStore.getCommitLog()).getdLedgerServer().getdLedgerLeaderElector().addRoleChangeHandler(roleChangeHandler);
}
this.brokerStats = new BrokerStats(defaultMessageStore);
//load plugin
MessageStorePluginContext context = new MessageStorePluginContext(messageStoreConfig, brokerStatsManager, messageArrivingListener, brokerConfig);
this.messageStore = MessageStoreFactory.build(context, defaultMessageStore);
this.messageStore.getDispatcherList().addFirst(new CommitLogDispatcherCalcBitMap(this.brokerConfig, this.consumerFilterManager));
} catch (IOException e) {
result = false;
log.error("Failed to initialize", e);
}
}
result = result && this.messageStore.load();
if (result) {数据写入流程
我们就根据此图来解释调用关系,展示了仅 RocksDB 模式以及默认模式下开启 RocksDB 双写的 CQ 数据写入和更新过程。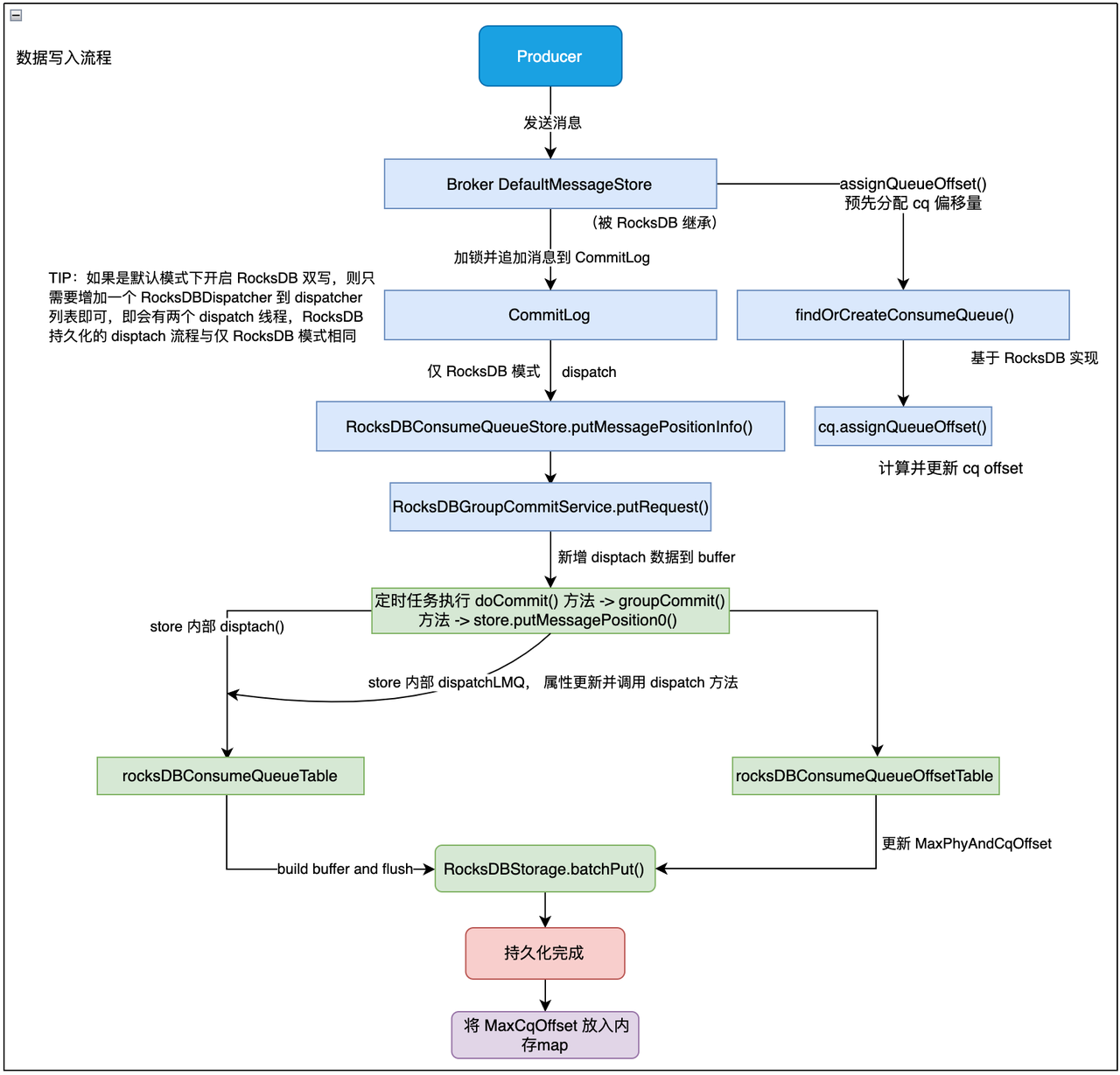
Dispatch 代码实现
如上所示,当我们开启双写后,将按照如下流程把 LMQ,CQ 数据同时异步写入一份到 RocksDB 中。
当开启双写后,会调用 enableRocksdbCQWrite 方法,这里会增加一个新的 RocksDBDispatcher,之后在 Dispatch 时会遍历 Dispatcher 列表并调用对应的 dispatch 方法:
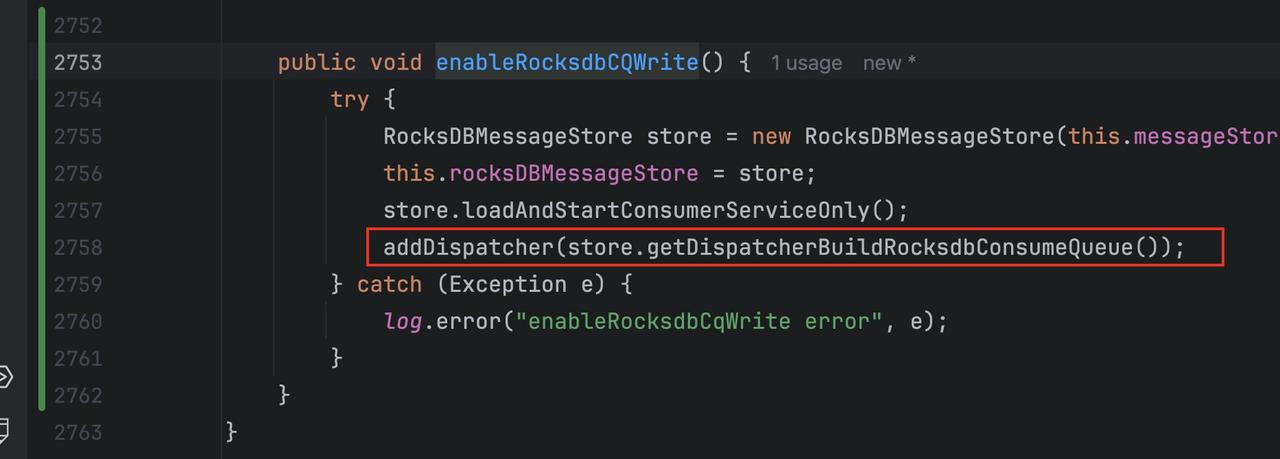
当调用 dispatch 方法时,会调用 Messagestore 的 putMessageInfo 进行 CQ 文件的更新。并且这里的 RocksDB 是基于 GroupCommit 的,也就是在 RocksGroupCommitService 中先追加数据到 buffer,然后有个定时任务去定时把缓存数据通过 store 对象进行持久化。
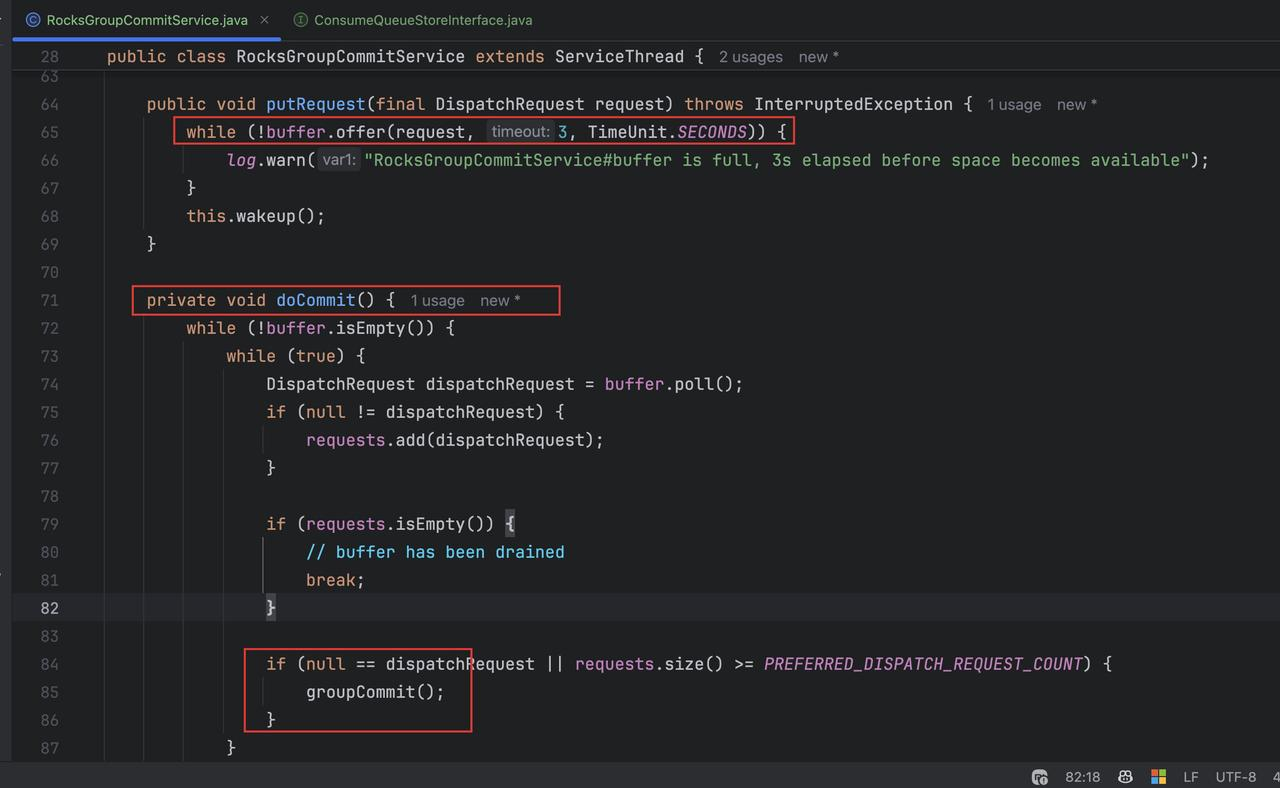
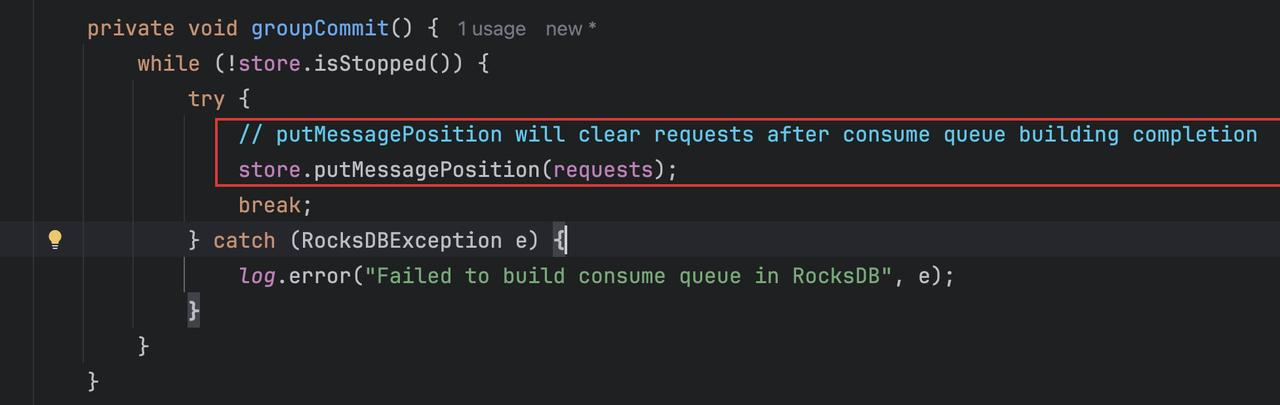
最终会调用到 RocksDBMessageStore 里的 putMessageInfo 0 方法,根据 dispatchEntry 把表数据构建出来,可以看到这里的三个 dispatch 方法,dispatchLMQ,dispatch 普通 CQ:
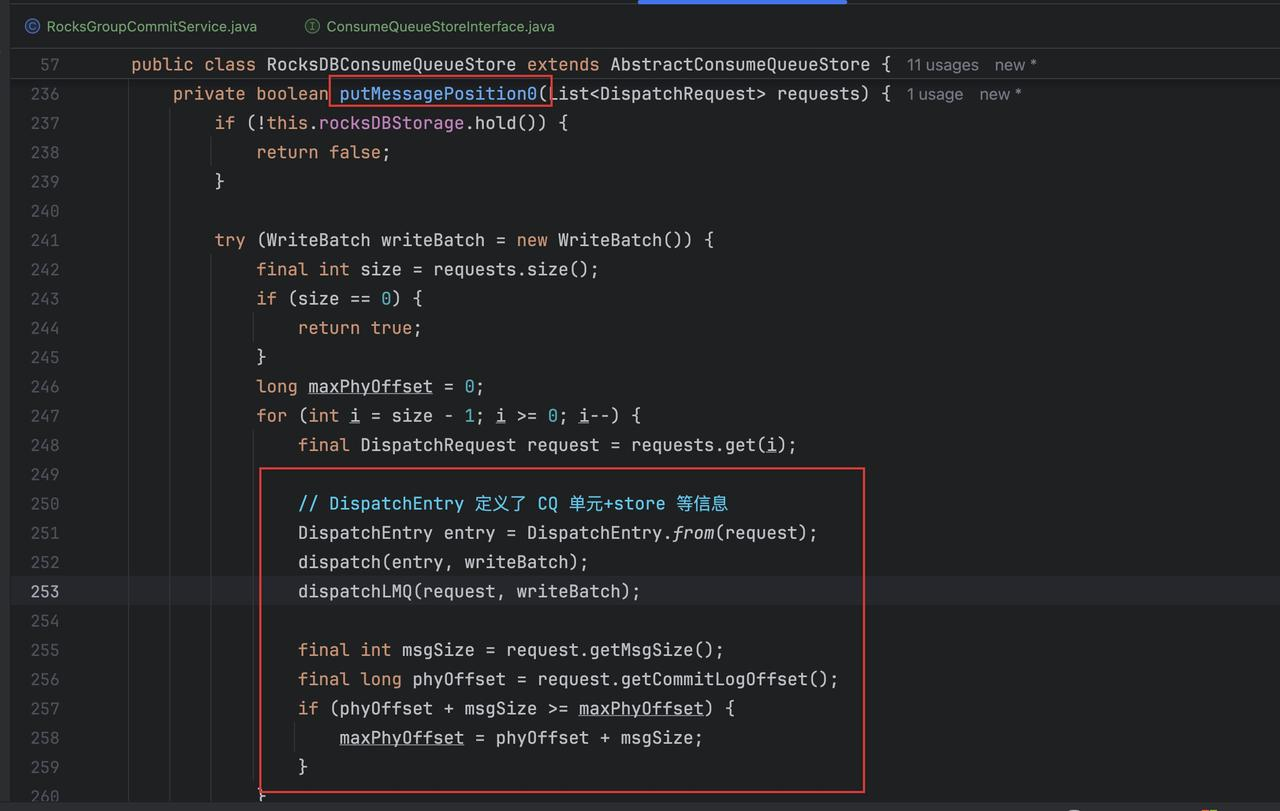
其中 dispatch 是一般 cq 数据的持久化,dispatchLMQ,则是在 dispatch 前进行一些属性的更新。
- 最终调用 offset 表的方法以及 RocksDB 存储对象的批量方法把数据写入到本地和堆中,这样数据就写了一份到 RocksDB 中了:
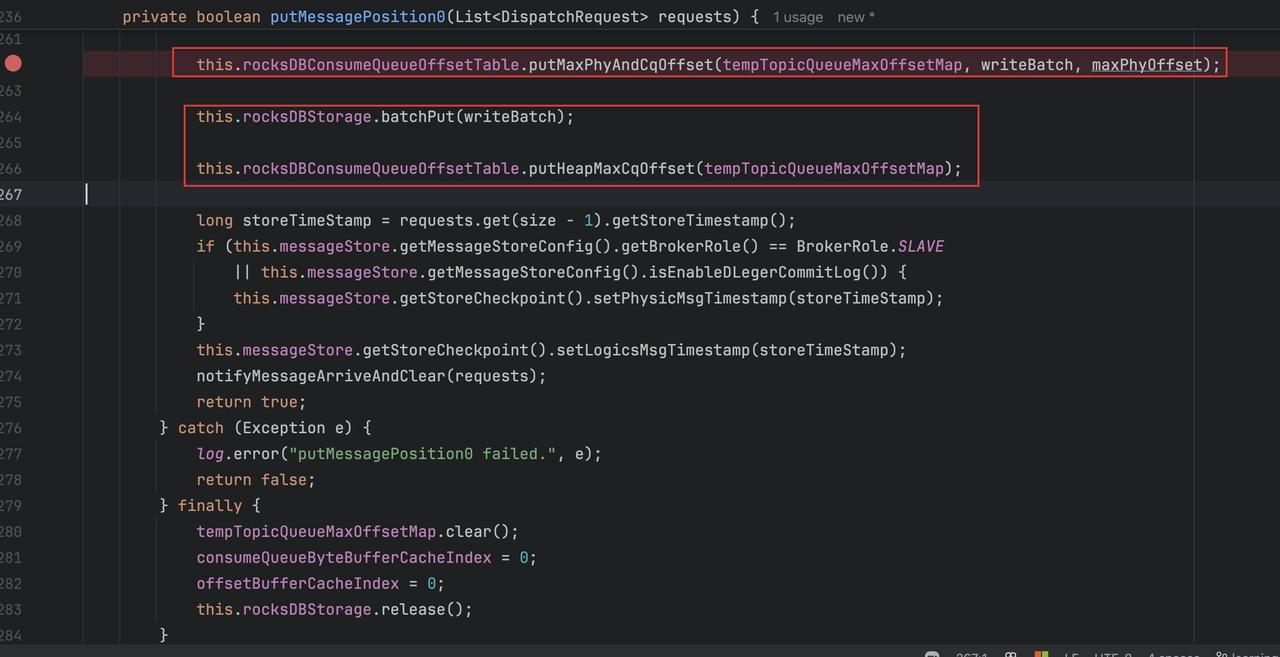
AssignOffset 代码实现
当 CommitLog 的 asyncPutMessage 方法被调用时,在 CommitLog 持久化消息前,会先进行 CQ offset 的分配。defaultMessageStore.assignOffset(messageExtBatch);其内部会根据事务类型,调用 ConsumeQueueStore 接口的 assignQueueOffset 方法进行 ConsumeQueue 的获取(如果没有则创建),并进一步调用 ConsumeQueue 对象的 assignQueueOffset 方法进行 maxOffset 的计算并更新。
以原版为例:
@Override
public void assignQueueOffset(QueueOffsetOperator queueOffsetOperator, MessageExtBrokerInner msg) {
String topicQueueKey = getTopic() + "-" + getQueueId();
long queueOffset = queueOffsetOperator.getQueueOffset(topicQueueKey);
msg.setQueueOffset(queueOffset);
}以 RocksDB 为例:
@Override
public void assignQueueOffset(QueueOffsetOperator queueOffsetOperator, MessageExtBrokerInner msg) throws RocksDBException {
String topicQueueKey = getTopic() + "-" + getQueueId();
Long queueOffset = queueOffsetOperator.getTopicQueueNextOffset(topicQueueKey);
if (queueOffset == null) {
// we will recover topic queue table from rocksdb when we use it.
queueOffset = this.messageStore.getQueueStore().getMaxOffsetInQueue(topic, queueId);
queueOffsetOperator.updateQueueOffset(topicQueueKey, queueOffset);
}
msg.setQueueOffset(queueOffset);
}可以看到 RocksDB 模式下,会在内存中没有对应 ConsumeQueue 的情况下从数据库中获取并更新内存集合。
RocksDBConsumerQueueStore
基于 RocksDB 存储类来操作数据库表,比如 CQ 表和 Offset 表(分别对应 RocksDBConsumeQueueTable 和 RocksDBConsumeQueueOffsetTable),并进一步实现更多方法,与原版 ConsumeQueueStore 区别如下:
由于统一了抽象接口方便统一调用,因此原版在此基础上又新增了一些方法,如并发 recover 会在方法后加提示。
方法实现对比
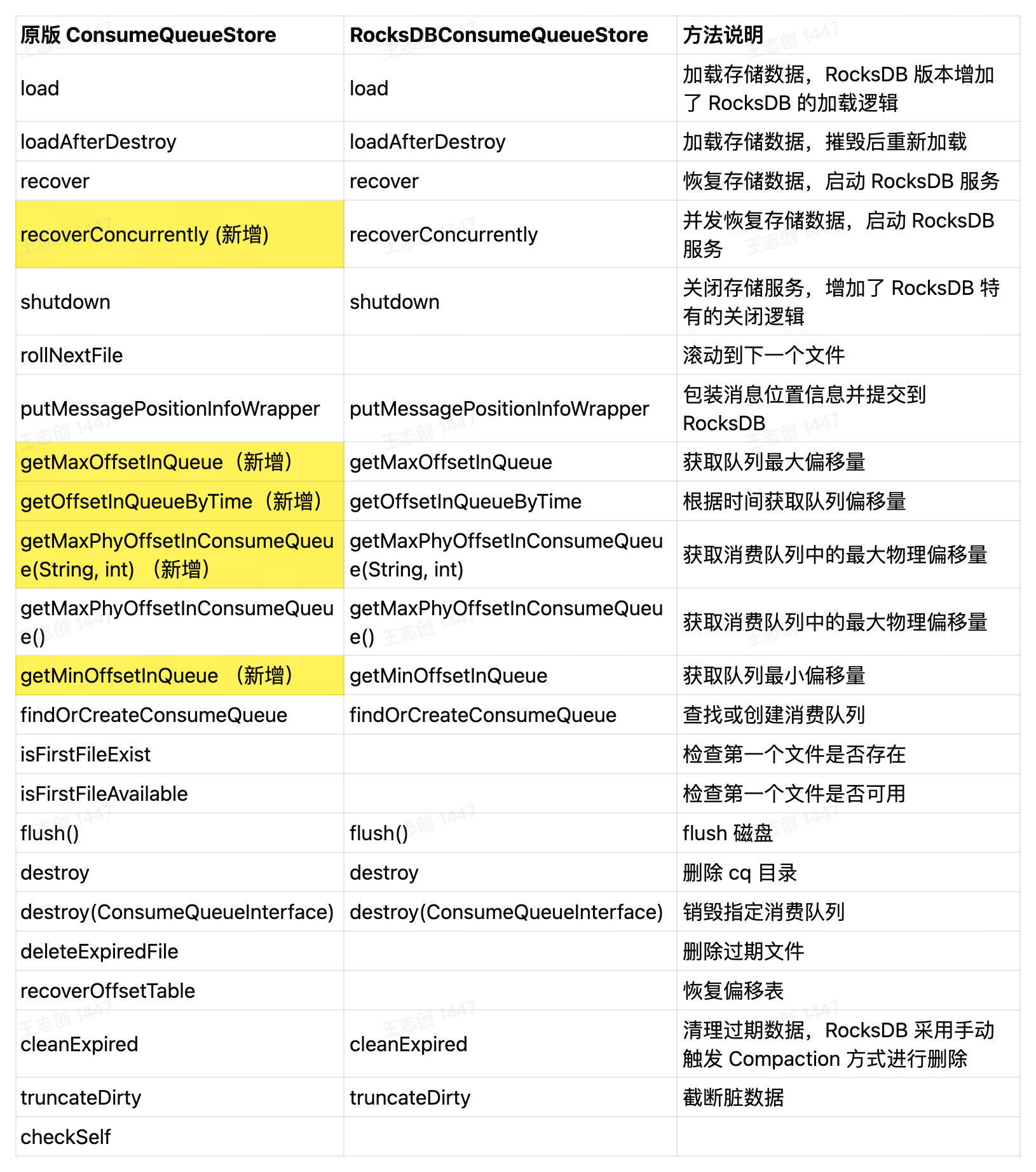
RocksDB 特有方法

RocksDBMessageStore
继承自 DefaultMessageStore 并继承了CleanConsumeQueueService、FlushConsumeQueueService 以及 CorrectLogicOffsetService 服务,利用 RocksDB 来实现。其中需要注意的是:
对于
FlushConsumeQueueServiceRocksDb 是不需要的,因此重写了空的 run 方法。因为我们不需要持久化 CQ 文件,只需要放到 RocksDBConsumerQueueStore 中维护即可。并且我们也不需要开启 WAL,因为 CommitLog 中包含了完整了 CQ 单元信息,我们可以根据这个进行重建。对于
CleanConsumeQueueService,如果需要删除过期的数据,只需要手动触发 Compaction 即可,根据自定义的 RocksDBCompactionFilter 可以在 Compaction 过程中进行自动删除。同时还需要删除相应的 index 文件。对于
CorrectLogicOffsetService,同样实现空的 run 方法,原因我们之前已经说过,不需要利用定时线程去判断逻辑偏移量是否过期,而是在使用时再进行判断。
CQ 相应表的删除
当 Topic 被删除时,需要删除 CQ 存储单元和 Offset。分为 ConsumeQueueTable 以及 OffsetTable。RocksDBConsumeQueueStore 调用 destroy 方法:
@Override
public void destroy(ConsumeQueueInterface consumeQueue) throws RocksDBException {
String topic = consumeQueue.getTopic();
int queueId = consumeQueue.getQueueId();
if (StringUtils.isEmpty(topic) || queueId < 0 || !this.rocksDBStorage.hold()) {
return;
}
try (WriteBatch writeBatch = new WriteBatch()) {
this.rocksDBConsumeQueueTable.destroyCQ(topic, queueId, writeBatch);
this.rocksDBConsumeQueueOffsetTable.destroyOffset(topic, queueId, writeBatch);
this.rocksDBStorage.batchPut(writeBatch);
} catch (RocksDBException e) {
log.error("kv deleteTopic {} Failed.", topic, e);
throw e;
} finally {
this.rocksDBStorage.release();
}
}进一步分析两表的删除:
- ConsumeQueueTable: destroyCQ()
RocksDB 是支持范围查询的,这个范围是根据字节的字典序排序的,因此之前提到过的 Ctrl_1 标识,实际上在这里发挥的了作用,首先看 RocksDBConsumeQueue 表:
(所在类:RocksDBConsumeQueueTable)首先是调用的主方法,其中有两个构造 CQ 文件起点和终点的方法 buildDeleteCQKey,实际上是拼接了 Ctrl0 和 Ctrl2 的标识,利用字典序的大小关系确定删除的范围来删除 cq 文件,很巧妙。
public void destroyCQ(final String topic, final int queueId, WriteBatch writeBatch) throws RocksDBException {
final byte[] topicBytes = topic.getBytes(StandardCharsets.UTF_8);
final ByteBuffer cqStartKey = buildDeleteCQKey(true, topicBytes, queueId);
final ByteBuffer cqEndKey = buildDeleteCQKey(false, topicBytes, queueId);
writeBatch.deleteRange(this.defaultCFH, cqStartKey.array(), cqEndKey.array());
log.info("Rocksdb consumeQueue table delete topic. {}, {}", topic, queueId);
}
// 拼接
private ByteBuffer buildDeleteCQKey(final boolean start, final byte[] topicBytes, final int queueId) {
final ByteBuffer byteBuffer = ByteBuffer.allocate(DELETE_CQ_KEY_LENGTH_WITHOUT_TOPIC_BYTES + topicBytes.length);
byteBuffer.putInt(topicBytes.length).put(CTRL_1).put(topicBytes).put(CTRL_1).putInt(queueId).put(start ? CTRL_0 : CTRL_2);
byteBuffer.flip(); // buffer 翻转,刚好让 Ctrl0 和 2 组成了一个区间。
return byteBuffer;
}- OffsetTable: destroyOffset()
public void destroyOffset(String topic, int queueId, WriteBatch writeBatch) throws RocksDBException {
final byte[] topicBytes = topic.getBytes(StandardCharsets.UTF_8);
final ByteBuffer minOffsetKey = buildOffsetKeyByteBuffer(topicBytes, queueId, false);
byte[] minOffsetBytes = this.rocksDBStorage.getOffset(minOffsetKey.array());
Long startCQOffset = (minOffsetBytes != null) ? ByteBuffer.wrap(minOffsetBytes).getLong(OFFSET_CQ_OFFSET) : null;
final ByteBuffer maxOffsetKey = buildOffsetKeyByteBuffer(topicBytes, queueId, true);
byte[] maxOffsetBytes = this.rocksDBStorage.getOffset(maxOffsetKey.array());
Long endCQOffset = (maxOffsetBytes != null) ? ByteBuffer.wrap(maxOffsetBytes).getLong(OFFSET_CQ_OFFSET) : null;
writeBatch.delete(this.offsetCFH, minOffsetKey.array());
writeBatch.delete(this.offsetCFH, maxOffsetKey.array());
String topicQueueId = buildTopicQueueId(topic, queueId);
removeHeapMinCqOffset(topicQueueId);
removeHeapMaxCqOffset(topicQueueId);
log.info("RocksDB offset table delete topic: {}, queueId: {}, minOffset: {}, maxOffset: {}", topic, queueId,
startCQOffset, endCQOffset);
}CQ 脏数据截断 (truncateDirty)
我们不需要截断 RocksDBConsumeQueueTable 中的脏 CQ,因为 RocksDBConsumeQueueTable 中的脏 CQ 将在附加新消息时被新 KV 重写,或者在删除主题时被清理。但是 RocksDBConsumeQueueOffsetTable 中的脏偏移信息必须被截断,因为我们使用 RocksDBConsumeQueueOffsetTable 中的偏移信息来重建 topicQueueTable(RocksDBConsumeQueue#increaseQueueOffset),要保证偏移量正确。
发展前景
Meta 数据存储
RocketMQ 中 Topic 和 Subscription 的数据较大且频繁更新,同样可以考虑用 RocksDB 来做,目前社区也有了相关的实现,问题在于:
在十万级甚至百万级的 Topic 和 Subscription 场景下,频繁的创建、更新与删除操作会触发元数据的持久化,而元数据的持久化是完整写入而并不是 append only。
这些操作会生成大量的大内存对象(如
topicConfigTable的 JSON 字符串),在内存紧张时可能直接分配到老年代,导致频繁 Full GC。(read -> update -> write)
性能提升
ref: RocketMQ 引入 RocksDB
稳定性分析
RocksDB 开启后只对 CQ 文件的读写有影响,不再采用独立 CQ 文件的方式进行管理,并且 RocksDB 提供了更高的扩展性,我们可以自定义压缩策略等配置,这样在高并发场景下,不需要频繁的对 CQ 文件进行操作,并且减少了 CommitLog 写入时对 CQ 的更新占用,能够提供更加稳定可靠的消费环境。
成本分析
引入了新的组件,成本会如何变化。因为是嵌入式的数据库,且是单机的,我们是不是可以把它当做一个本机的文件操作和存储系统?并且本质上还是写到磁盘,可能变化是不大的,但是对于内存的要求更高。
同等规模的 CQ 数据存储,RocksDB 由于自身的数据压缩,以及设计好的表和数据格式,RocksDB 占用相对减少了 2/3 的存储占用,且性能更优。
| Consumer Queue 规模 | RocksDB | 文件系统 |
|---|---|---|
| 2w | 40 GB | 113 GB |
| 10w | 100 GB | 566 GB |
对于文件系统的计算:queue size (5.x MB) * num 数量
MQTT
对于 MQTT,同样可以利用 RocksDB 作为存储,来解决一些问题,例如:
基于 LMQ 优化 MQTT 的场景,可以将 LMQ 相关数据放到 RocksDB 中存储和管理。
MQTT 元数据的存储和管理。
其他 KV 数据库可行性分析
既然上面的接口是扩展性的,说明也可以扩展其他的 KV 数据库,简单分析一下其他数据库是不是也能实现会不会有更加优秀的表现。



