1. 前言
面试的时候问了这些。所以要弄清楚具体的查询过程,以及跳表的结构,还有实现利用 ZSET 实现排行榜是怎么从跳表上获取元素的。怎么获取某个数据的名次。
老规矩,先来一个对整体的大概了解。
- 跳表的结构,多层链表,链表节点中有多个指针(从而形成多层链表)
- 跳表进行范围查询,不是以两端点为准查到底层后,返回两端点之间的值。而是通过从顶层查询范围查询中的 start 开始,大于等于 start 的第一个元素,找到之后直接往下层走,继续找第一个大于等于 start 的元素,最后到达底层,就在底层链表上,往右遍历,直到遇到第一个大于 end 的元素为止结束查询。
- 跳表进行单点查询(也就是查询某个元素的具体权重),是通过哈希表实现的,跳表的多层结构只负责查询节点值,而不负责权重的存储。这样一想确实是,哈希表存储这种键值对不是更好嘛,查询效率是 O(1)。比如 LRU 算法,不也是用哈希表来存储缓存值,并通过双向链表表示元素的使用情况嘛,最新插入的元素在头部或者尾部,具体实现决定。
总之呢,就是范围查询是由跳表实现的,单点查询由哈希表实现。而这两种操作对应了 ZSET 的命令:ZRANGEBYSCORE 返回权重范围内的元素。ZSCORE获取某个元素的权重值。
2. 跳表结构
那现在就开始具体源码分析吧,基本查询过程就上面分析的那样。这里就重在理解其本质。
2.1. ZSET 的结构体
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;这里要知道,所有的数据结构其底层都是通过 RedisObject 把所有这些数据结构封装了(比如 zset, sds, listpack 等),然后类似哈希表那种,在桶数组上某些节点用指针指向具体的数据结构实体。从而保证 Redis 能存储各式各样的数据。
可以看出嘛,是由字典 dict 以及跳表实现。具体字典实现参考:Redis–永久笔记–dict字典结构 ,而跳表就仔细讲讲。
2.2. 跳表的节点
比如下面的跳表结构: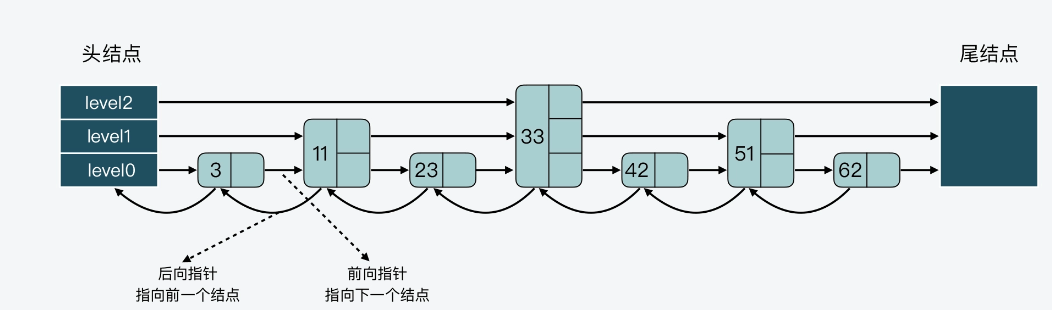
可以看到,在 level 0 上一共有 7 个结点,分别是 3、11、23、33、42、51、62,这些结点会通过指针连接起来,同时头结点中的 level0 指针会指向结点 3。然后,在这 7 个结点中,结点 11、33 和 51 又都包含了一个指针,同样也依次连接起来,且头结点的 level 1 指针会指向结点 11。这样一来,这 3 个结点就组成了 level 1 上的所有结点。
最后,结点 33 中还包含了一个指针,这个指针会指向尾结点,同时,头结点的 level 2 指针会指向结点 33,这就形成了 level 2,只不过 level 2 上只有 1 个结点。
这时候就想到了,这具体是咋划分的呢,也就是非底层节点到底选哪些下一层的节点作为这一层的节点,选多少个节点呢?
这个在后面再说。[[Redis–永久笔记–跳表skipList数据结构#3. 跳表的其他参数]]
看一下跳表节点的结构体源码:
typedef struct zskiplistNode {
sds ele; //Sorted Set中的元素
double score; //元素权重值
struct zskiplistNode *backward; //后向指针
//节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[]; // 就是多层链表中每一层的各节点的前指针以及跨越的节点个数
} zskiplistNode;ele是 SDS 类型的,也就是存储加入到 zset 的元素值,而score是该值的权重,用来作为排序的依据。backward好奇怪,你指向前一个节点,为什么要命名成这样 ,back? 其实好像也可以理解,因为这个指针是为了方便从链表的尾部往前进行遍历,所以从后开始就是 back 喽。- 其实是可以看到里面那个多层链表结构体
zskiplistLevel是一个数组,也就是说明每个节点都有“向上延申的可能”。并且还有跨度表明当前层每隔几个节点就连接一次,以及 forward 指针指向每个跨度下的节点。连接成一个新的链表。
2.3. 跳表是怎么获取元素对应的在整个跳表中的顺序的
- 如果没懂的话,可以这样理解,根据跳表假如想获取某个元素的权重在整个 ZSET 中的元素顺序(正序或逆序),你遍历之后,不是要到达底部嘛拿元素嘛,但是你遍历到这个元素之后,发现这个顺序你并不知道是在哪(根据权重排序后,元素的顺序),所以你需要往前遍历找到当前层(level 0)的头节点,来判断自己在哪个位置。这样的话,你这个效率就是
O(n)了,很慢啊。
跳表咋解决呢?
- Redis 这个跳表的实现就很巧妙,它是在查询过程中,每个 node 节点里面不是有跨度嘛,就是那个 span,只要进行累加,这样到达底部的时候,就能得到该节点元素在跳表元素中的全局位置。而那个 forward 指针正好起到一个规范查询过程的一个作用。
还是不懂,我把图标一下。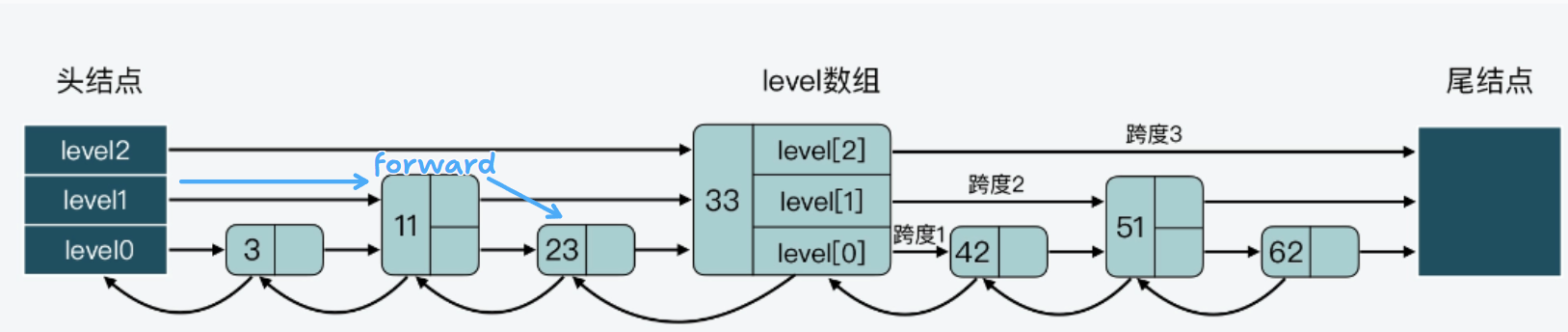
比如这个 23,跨度和就是 2+1=3,即 level 1 中 11 节点的跨度+level 0 的23 节点跨度。
这个是用来进行 Zset 特有的排序 RANK 功能。比如命令:Zrank 正序 和 ZREVrank 反序。
获得范围查询元素的顺序也很方便,就是找到初始节点 start 所在的位置,因为也进行了累加,所以它的顺序就是确定的,所以呢其他元素只要也依次累加 span 即可(最底层 span 为 1 嘛)就可以得到元素所在的全局顺序。
2.4. 跳表本身的结构体定义
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;可以看到有一个头节点,尾节点,说明我们可以从前往后,也可以从后往前遍历这整个跳表,而且刚才也讲了跳表的节点都有指向前者的指针以及后者的指针。
然后呢,这个就是 ZSET 中的一部分,跳表。
3. 跳表的其他参数
怎么设置的层数?每层节点个数怎么确定。跳表查询效率怎么样?
Redis源码剖析之跳表(skiplist) - 知乎 (zhihu.com)
- 首先看查询效率
假如我们要查询元素 13,那么流程大概是这样,也就是发现本层下一个节点值大于目标节点值就从现在的位置下去,继续往后找。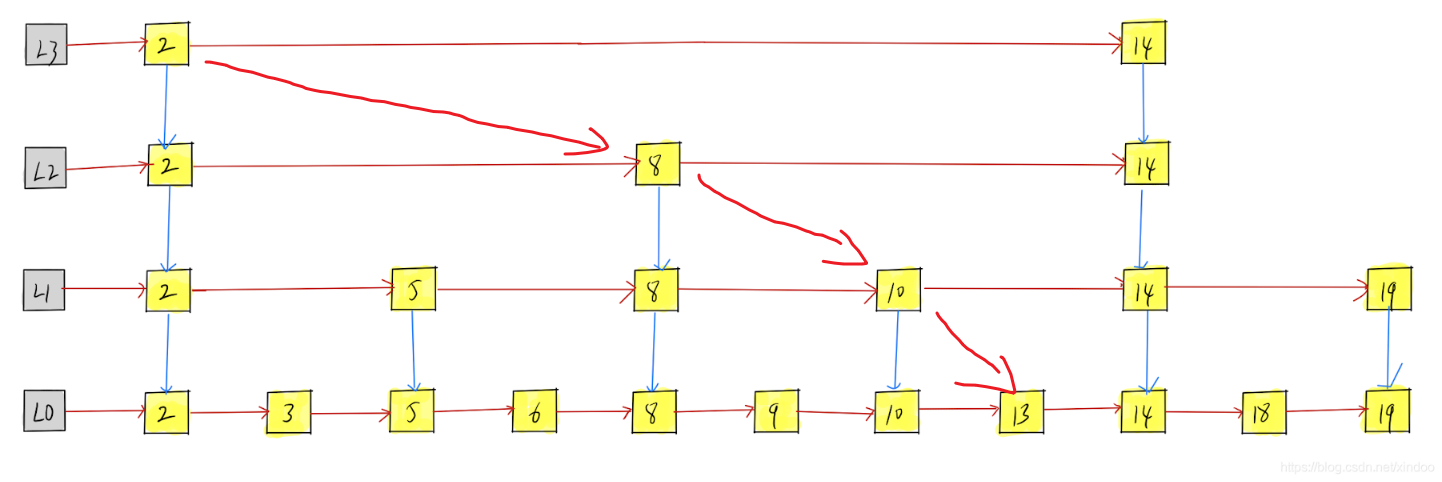
此时的节点设置的是上一层是下一层的节点的二倍,这样查询的过程相当于二分查找,比如有序数组上的二分,每次找到中间元素进行判断,这个跳表相当于把所有的中间值拿出来到各层链表上,我们每次直接从上层判断中间值,遇到就下去到达底层拿到目标数据。也就提高了单链表 O(n) 的查询效率,变成了 O (logn)。
而且层数越多,查询的效率越快,但是消耗空间就越多。
- 上层节点的值不固定,由随机算法决定。
如上图这种每两个节点之间拿出节点到上层,保证 2:1 的节点比,在进行元素的删除和插入时,你就需要重新调整各层链表的指针,比如上面个节点有多层,这个元素删掉后需要修改大量指针进行重构,以保证有序以及比例关系。所以是很不方便的。
Redis 的跳表采用的是zslRandomLevel 函数 随机决定每个节点的层数。(也就是给每个节点初始化为可能是多级结构,也可能只是底层节点)。
具体是函数内部会生成一个随机数,这个随机数如果小于规定的概率值(大概 1/4 概率抽到),这个节点层数就增加一层。所以每个节点增加层数的概率大概为 1/4,当插入和删除节点的时候,只要修改待修改的节点的指针即可。
可能不太理解,为什么这样就能减少插入和删除时的调整开销了呢?
- 因为上面如果需要保证严格的 2:1 或者其他比例关系,你插入和删除节点就需要保证大部分的节点都需要进行调整以保证比例关系。所以开销大。
- 通过随机生成函数,每个节点的层数不定,但是又使全局保证了一种平衡(因为有概率嘛),当插入节点和删除节点的时候,只需要在目标值相邻的节点之间建立指针关联即可。不需要调整其他节点的指针,也就提高了效率。
4. 跳表和哈希表联用
我们上面其实已经知道了,哈希表是用来快速判断整个 ZSET 中是否存在响应的值,并且可以以 O(1) 时间复杂度拿到目标值对应的权重(ZSCORE 命令)。
然后呢跳表是用来快速定位根据权重排序的元素顺序(累加跨度 span)已经快速查询目标权重范围内的元素(查询到底层进行再遍历)。
这两个算是两个索引,所以需要在插入的时候对两个索引都要进行维护(插入)。
插入元素过程:
在调用插入元素的函数 ZsetAdd 时,会先通过 dictFind 函数里判断是否存在这个元素是,如果不存在,则分别进行跳表或者压缩列表以及哈希表元素的插入。如果存在,则判断是否需要更新权重,如果需要更新,则会调用 zslUpdateScore 函数进行跳表节点中对应节点的权重值更新,然后把哈希表的权重指针指向跳表中该节点的权重值。(这样就能保证哈希表指向的就是最新的权重值)
zadd 函数具体内容:
//如果采用ziplist编码方式时,zsetAdd函数的处理逻辑
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
...
}
//如果采用skiplist编码方式时,zsetAdd函数的处理逻辑
else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
//从哈希表中查询新增元素
de = dictFind(zs->dict,ele);
//如果能查询到该元素
if (de != NULL) {
/* NX? Return, same element already exists. */
if (nx) {
*flags |= ZADD_NOP;
return 1;
}
//从哈希表中查询元素的权重
curscore = *(double*)dictGetVal(de);
//如果要更新元素权重值
if (incr) {
//更新权重值
...
}
//如果权重发生变化了
if (score != curscore) {
//更新跳表结点
znode = zslUpdateScore(zs->zsl,curscore,ele,score);
//让哈希表元素的值指向跳表结点的权重
dictGetVal(de) = &znode->score;
...
}
return 1;
}
//如果新元素不存在
else if (!xx) {
ele = sdsdup(ele);
//新插入跳表结点
znode = zslInsert(zs->zsl,score,ele);
//新插入哈希表元素
serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
...
return 1;
}
..- #task 跳表 skipList 数据结构 ✅ 2024-02-29
5. 为什么用跳表,不用红黑树?
- 内存占用更少。平衡树每个节点包含 2 个指针,redis 中平均指针 1.33 个。
- 在做范围查找的时候,跳表比平衡树操作要简单。跳表只需要在找到小值之后,对第 1 层链表进行若干步的遍历就可以实现。
- 从算法实现难度上来比较,跳表比平衡树要简单得多。因为红黑树涉及各种旋转保持平衡的操作。



