面试问到一千条 redis 命令来到,怎么进行优化,来减少处理时间。
之前没了解过,然后想的一些方案并不是这么有效,所以下来自己总结一下。
单机模式下
暂时先讲单机模式下的批处理优化。
通信携带命令条数不同导致效率不同
- 如果一次客户端到 redis 服务端的通信中只携带一条 redis 指令,那大概的总耗时就是:1 个来回时间 + 1 个 redis 处理命令时间。N 次就是 N 个来回时间 + N 条命令处理时间。
画个图吧: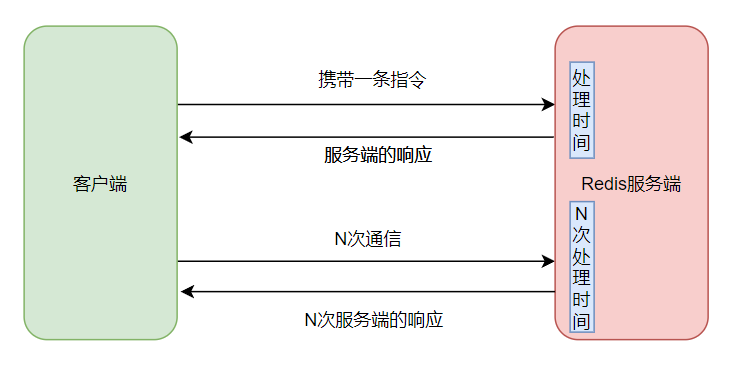
- 一次通信携带多条指令,减少总的通信次数。
这样的 N 条命令的总耗时就为:N/M 个来回时间,N 个处理时间。(M 代指每次携带的命令条数)。
图就不画了,应该能想象出来,不是重点。
- 总之:通信时间在 Redis 的使用过程中占大头,所以减少通信次数就是批处理优化的一个主要攻克点。
Redis 中怎么操作
我当时想到了列表 List 数据类型,但是列表好像并不算是一个批处理命令,然后就扯其他的了。
现在才醒悟,对啊,mset 和 hmset。就是专门用来做批处理的命令,怎么没想到类比 Mysql 分批插入大量数据呢。也就是一次把多个 redis 命令封装在一起作为一次通信发给 Redis 客户端。
语法
mset key1 value1 [ key2 value2]
hmset key field1 value1 [field2 value2]代码示例
如上,可以通过数组传递需要设置的批量 redis 命令,设置 String 类型的。并且 key 可以不变。而对于 hash 数据类型,其批量插入只能指定一个键。Set 类型的批量插入命令(SADD)也是有局限的(只能指定一个 set 的键)。
MSET 命令,数组批量插入示例: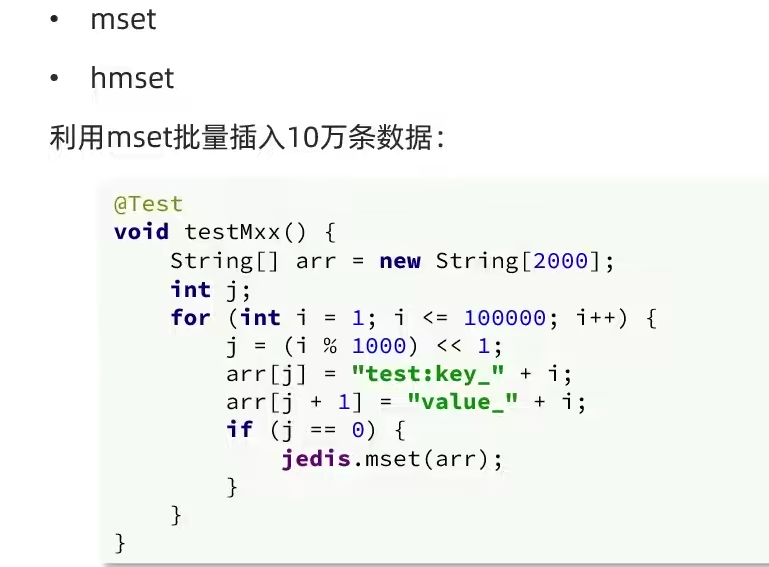
PipeLine 优化批处理执行
PipeLine 不管是 Jedis 还是 Redis 都提供的有,这个主要是用来把各种不同的 Redis 命令都装在一起,然后统一发送到 Redis 服务端。
与批处理命令不同的是,这个可以装”不同的命令”,也就是说可以解决 HMSET 和 SADD 中批量插入时只能指定一个 Key 的问题。你只要把多个 SADD 命令和 HMSET 命令装进来就行了。
示例:
- 模拟 MSET

PipeLine 的 sync() 命令就是发起一次通信请求到 Redis 服务端。
但是命令到达之后可能就会进入队列中等待,执行的顺序是有先后的,所以呢速度可能会比 mset 慢一些,但是好在对更多的数据类型都支持。
集群模式下
在集群模式下,如果批处理命令没有分配到同一个槽位(也就是同一个 Redis 节点),就会导致执行失败。所以在集群部署下做批处理就需要其他工具了。
TODO



