前言
RedoLog 如何保证事务特性中的持久性的,之前学习的是只知道是缓存中更新数据,然后刷新到磁盘,这个过程中也知道借助了 Redolog 来实现,但是不知道更细节的层面,比如存储引擎数据页层面。
所以呢就补充了一点内容记录一下。
1. Redo log 保证持久性
#redolog
Redo log,重做日志,记录“事务提交时数据页的物理修改”,用来实现事务持久性。
该日志文件由两部分组成: 重做日志缓冲 (redo log buffer)以及重做日志文件 (redo log file), 前者是在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都存到该日志文件中,用于在刷新脏页到磁盘, 发生错误时,进行数据恢复使用。
下面根据有无 redo log 日志文件分别区分持久化问题:
1.1. 假设没有 redo log 日志,正常的持久化过程。
首先要知道 InnoDB 引擎内部的存储结构:一个内存结构和一个磁盘结构;
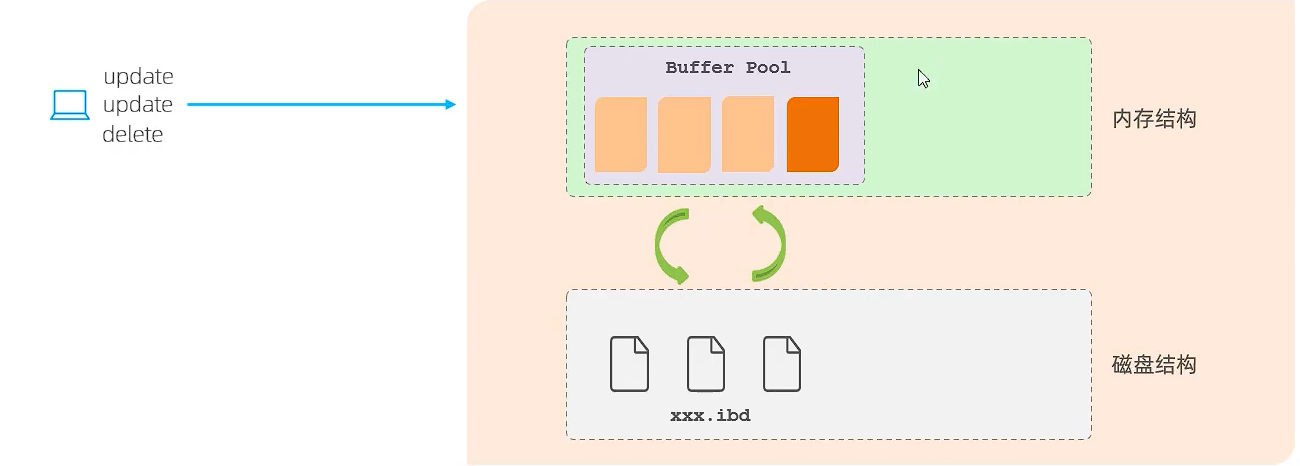
在进行一系列更新和删除操作前,Mysql 首先会从磁盘里读取相应的待修改数据到 buffer pool 内存中,这样一系列操作就会对内存中的这些数据进行修改,在事务提交前,内存中的数据就是所谓的脏数据。事务提交后会将脏数据刷新到磁盘完成持久化。
但是如果在刷新的过程中出错了,脏数据没有刷新到磁盘,但是事务已经提交,持久性就没法保证了。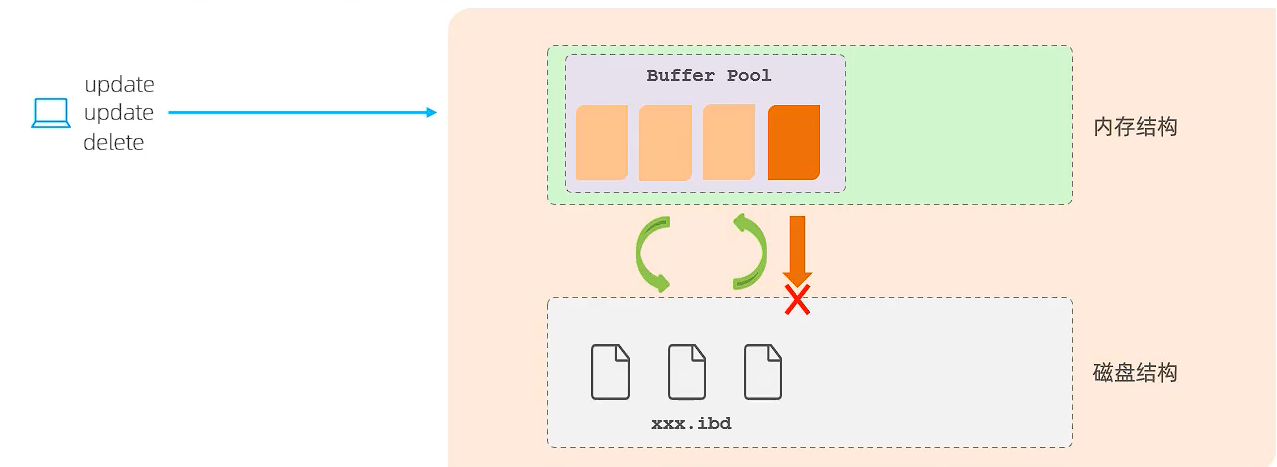
1.2. 使用 redo log,保证持久性的过程
先贴图: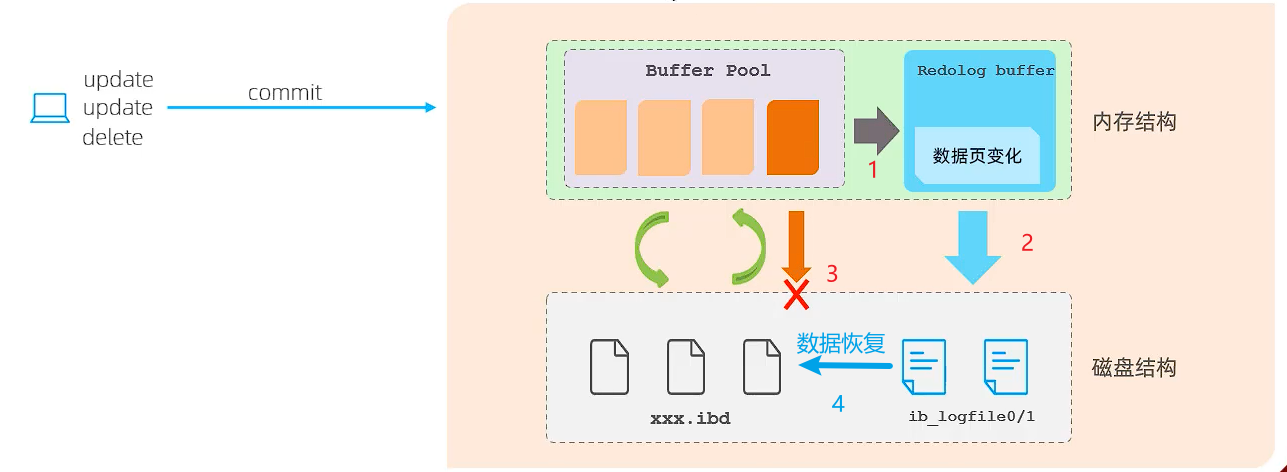
具体顺序已用序号标出:
- 在对内存中读取到的数据执行更新操作时,会同时将修改的数据存储到
redo log buffer缓冲中 - 并且可以根据一定的策略,将 redo log buffer 的数据同步到本地磁盘上的 redo log 文件中,然后再将修改后的数据同步到磁盘中.(这个应该是在事务提交之后,记录全部的数据更新)。
- 假如此时数据库宕机(脏数据刷盘失败),那数据库重启之后会判断修改的数据是否真正同步到了磁盘,如果没有,那就通过 redo log 在本地磁盘上进行数据的”再”同步。从而实现持久化(并且这个过程是顺序 IO,速度很快)。
其他问题
有个问题:redo log buffer 同步到 redo log 到底是事务提交前还是事务提交后?。
字节一面:事务还没提交的时候,redolog 能不能被持久化到磁盘呢?-腾讯云开发者社区-腾讯云 (tencent.com)
T 2:为什么不直接在页更新之后,就立即刷盘?
- 假如我们在页更新之后,也就是数据库对
buffer pool内的数据更新后, 哪怕只是更新几个字节的数据,那也要把这一整页的 16 kb 数据都同步到磁盘,那语句多了,同步次数也多,性能也就下降了。- 且执行一条 sql 语句,也有可能导致磁盘上的数据进行多次页分配,这个过程是随机 IO,寻址过程比较占内存。
- 通过 redo log 的话,由于是顺序写入的 redo log 文件,所以速度会很快。



