衍生问题:
- ConcurrentHashMap 和 HashTable 的区别;
- ConcurrentHashMap 和 HashMap 的区别;
本文介绍 ConcurrentHashMap 是怎么实现线程安全的,主要根据其在不同 JDK 版本下的实现。
ConcurrentHashMap 的底层数据结构以及线程安全实现
在 JDK 1.7 时,采用分段 Segment 数组+链表实现。JDK 1.8 以后采用和 HashMap 1.8 时的一样,都是数组 + 链表/红黑树。但是这个数组的节点是一个一个的 Node 节点。
JDK 1.8 之前:
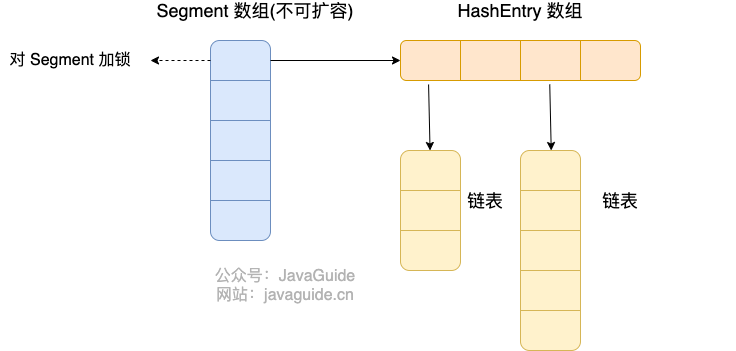
实现原理:指对数据进行分段,对每一部分数据分别加一个分段锁 Segment,每一个段对应一个 HashEntry 数组,这个数组采用 key-value 结构存储键值对数据,值的类型为链表。当需要对某个 HashEntry 数组进行修改时,会先获取对应的 Segment 锁。
多线程对于同一段的操作会造成堵塞,不同段可以并发。
Segment :继承了 ReentrantLock 锁,所以是一种可重入锁,由于实现方式的底层是一个 Segment 数组,所以段的个数是不可改变的(默认大小 16)。
可重入锁不清楚了可以参考:JUC–永久笔记–AQS队列同步器与ReentrantLock可重入锁
JDK 1.8 之后
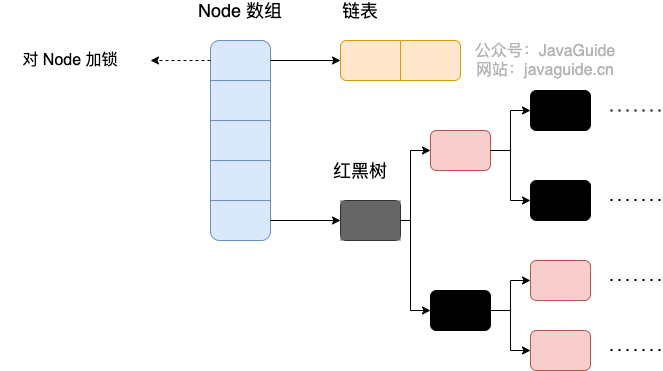
通过 Node 数组 + CAS + synchronized 实现并发安全;结构为数组 + 链表/红黑树。
与 JDK 1.8 之前的实现方式对比:
- 数据结构不同
- 锁的粒度更细,改用了 Node 作为锁的对象
- 优化了出现 Hash 冲突时的数据存储,和 HashMap 1.8 之后类似,数组和链表超过一定长度会转换为红黑树。
- 由于是使用 Node 数组,节点个数更多,所以并发度更高。
和 HashTable 的区别
底层数据结构:
- HashTable 底层是由桶数组 + 链表实现
- ConcurrentHashMap 1.8 之前是 Segment 数组+链表。1.8 之后是 Node 数组+链表/红黑树。
实现线程安全的方式不同:
- HashTable 是通过 Synchronized 进行加锁,当进行锁的时候会锁住整个桶数组,其他线程不能进行元素的修改和读取,竞争很激烈,因此效率较低。
- ConcurrentHashMap 1.7 的时候,当修改某个 entry 数组下的元素时,会把 entry 所在的 Segment 段加锁,其他线程如果也想访问到同一个 Segment 下的元素,就必须等待锁的释放。此时其实已经比 HashTable 的效率高很多了,但是仍然会发生线程竞争问题。因此 1.8 之后采用了 Node 数组+链表/红黑树实现,和 HashMap 的结构类似,一个 Node 数组对应一个链表或者红黑树,每次只需要锁住某个 Node 节点即可实现线程安全问题,这时锁的粒度更细,也就减少了线程竞争访问问题。
容量问题:
- HashTable 在初始化之后,Segment 数组就不能进行扩容了,是固定的,不够灵活。
- Node 数组由于是链表节点,因此可以无限扩容。
确实是链表节点。