SQL性能分析
进行 SQL 优化首先需要了解 sql 语句执行的情况,下面有三种分析方式。
下面三种重要性不高,还是主要看 explain:Mysql执行计划分析 | KTnoobStation (gitee.io)
查看执行频次
通过模糊查询语句判断当前数据库哪些操作是使用更多的(一般是查询最多)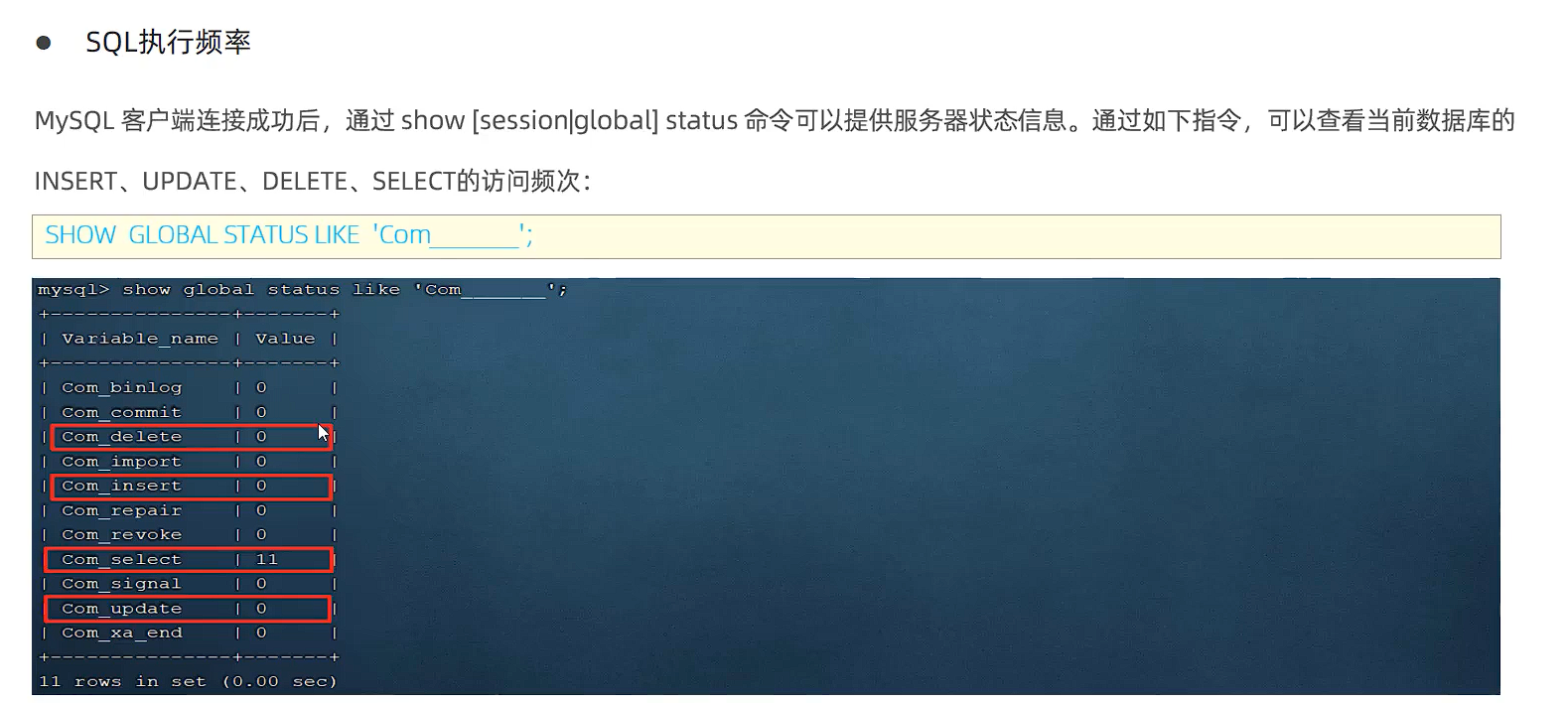
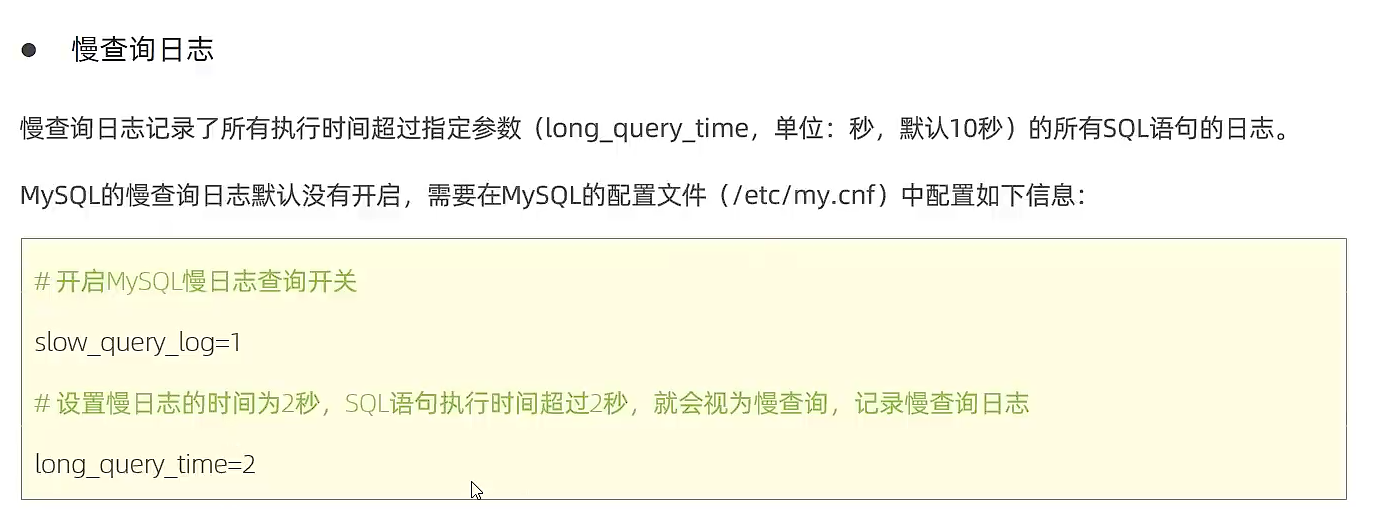
慢查询日志
慢查询日志会记录所有执行时间超过指定参数的 sql 语句。
默认未开启,可在配置文件中开启。
show profiles
主要可以记录所有 sql 语句在各个阶段的所花费的时间。
初始化,执行等等的过程耗费的时间。
SQL性能优化
包括插入优化、主键优化、order by 排序优化、group by 分组优化、limit 分页优化、count 计数优化、update 更新优化。
为避免长篇大论,简要概括每一条
insert 插入优化
即在大量数据插入的场景怎么优化的问题。
- 尽量采用批量插入,减少 insert 语句调用次数,如果量太多,可以分批次的批量查询。
- 手动提交事务,减少事务的开启和关闭次数。
执行一系列 insert 语句前开启事务,结束后手动提交。
- 按照主键的顺序插入。(涉及主键优化)
在待插入数据量极大的时候,可以采用 Mysql 的 load 命令(从文件直接加载到数据库表中)。
主键优化
聚集索引一般都是根据主键建立的,因此主键优化实际上就是优化聚集索引的建立。
插入数据时,尽量按照顺序插入,如数据库自增主键 AUTO_INCREMENT;
即插入时的数据主键值要是有序的,否则会产生页分裂和指针重指向的现象,导致效率下降。
页分裂,涉及到 InnoDB 的底层存储结构。参考 InnonDB架构和事务原理
在满足业务要求的前提下,降低主键的长度。
Order By 排序优化
尽量将已经存在有序索引的字段作为排序字段,这样可以避免排序操作,直接按照索引顺序返回数据。
建立索引时可以指定该字段的顺序,
create index index_name on table_name(age asc)联合索引同理,但是要注意使用 order by 命令时指定的顺序要和创建索引时的顺序相同,否则索引失效,还会走 filesort 。
- 通过 explain 命令得到的 extra 中可能会提示 using filesort 即表示读取到数据后,会在排序缓冲区 sort buffer 先排序,后面才会返回数据。
- 而使用索引就是 using index,不需要排序。
Group by 分组优化,也是尽量使用索引作为分组字段。否则会造成临时表的创建,导致效率降低;对应 using temporal
limit 分页查询优化
limit 分页语法:select * from table_name limit 0, 10; 指取第一条数据开始的前10 条数据。
会出现的问题
在大数据量情况下,比如查询第 5000000 以后的前 10 条数据,会特别慢。
因为 limit 5000000, 10 ,数据库需要排序前 5000010 条记录并只返回这 10 条数据,其他查询记录会丢失。
优化方式
使用覆盖索引 + 子查询。比如查询已经存在的聚集索引(或其他的覆盖索引),select id from table_name order by id limit 5000000, 10; 查询到这些 id 之后,外面再套一个父查询(根据 id 查数据),这样就可以极大减少需要查询的数据量,以提高效率。
例:
select s.* from tb_sku s, (select id from tb_sku order by id limit 9000000,10) a where s.id = a.id;
count 计数优化
count 计数语法:select count(*) from table_name
基于引擎实现产生的问题
MyIsam 引擎会将一个表的行数存在磁盘中,因此使用 count 效率很高。
InnoDB 引擎是将数据读出来,然后再累计计数。
Count 的累计计数有几种情况:
count (*),记录总行数,由于不取具体数据,只是计数,效率最高- count (具体字段),取具体字段值,如果没加 NOT NULL 约束则判断是否为空 NULL,如果不是则按行计数+1
- count (主键),取主键值,按行直接累加(主键一定非空)
InnoDB 引擎对count计数做了优化,会选用数据量较小的非聚簇索引进行统计。所以效率:count(*) ≈ count(常量) > count(id) > count(字段)
两种引擎在大数据量的情况下,效率差距巨大。
优化方式
尽量使用 count (*), 效率最高。
Update 更新优化
倒也不是优化,但是要规避一些操作;比如更新时,条件中尽量使用建立了索引的字段。
原因
- 当条件字段为有索引的字段,如主键值聚集索引或非聚集索引,开启事务后,Mysql 只会给这一行索引的数据加“行级锁”,这时候其他事务对这个表的其他数据更新或其他操作不会被阻塞。
- 当条件字段无索引,Mysql 会给这个表加“表级锁”,其他事务对该表的操作会被阻塞导致并发性能下降。
总结
擅用索引( ̄︶ ̄*))



