Date: 2023/9/29
本文目的是记录三种 redis 缓存出错的场景
- 缓存击穿
- 缓存穿透
- 缓存雪崩
一 . 缓存穿透
定义:
如果用户请求一个数据库中永远不存在的数据,比如查询 id 为 0 或负数时,服务端会先查 redis,发现没有,就会去转发到数据库查询,数据库中一定不会查询到该数据(id 自增),但是也会对数据库造成压力,如果有人知道了请求路径,就可以通过大量请求这样的 id,可能会导致数据库崩溃。
解决方法:
如果 redis 中不存在,转发到数据库中查询,如果查询不到,就把需要查询的 id (id <= 0)作为 key,value 设为 NULL,存到 redis 中,这样再次有一样的请求,就会直接返回 redis 中对应的空值;
当然,这里的 key 需要设置一个过期时间,否则会造成内存压力过大。
二 . 缓存击穿
定义:
当一个 redis 中某个 key 刚好失效的瞬间,大量请求该数据的请求就会被转发到数据库进行查询,只要数据量够大,也会导致数据库压力大甚至崩溃。
还有一种想法是:这个 key 长时间处于高并发状态,这时如果 key 突然失效,就会导致上述结果。
解决方法
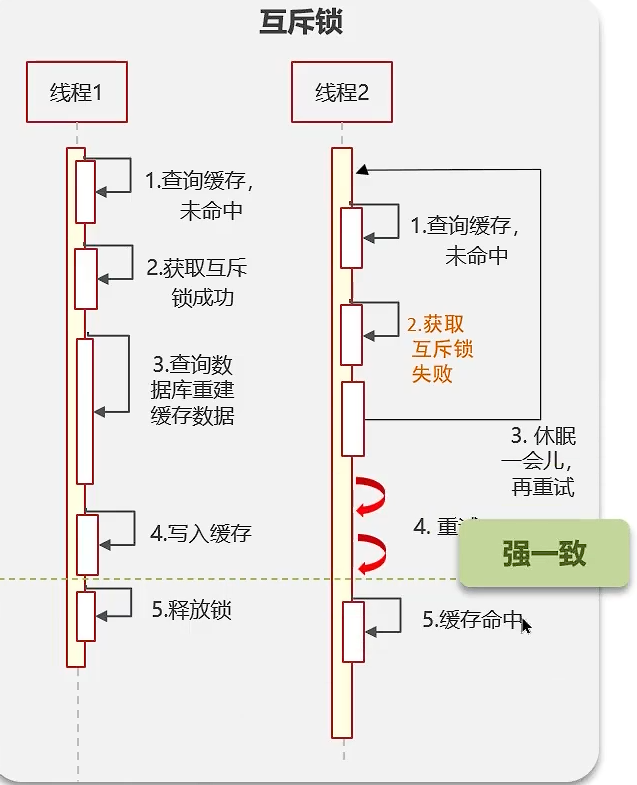
互斥锁
给线程添加互斥锁,当前线程 1 如果查询 redis 缓存查询不到就会获取互斥锁,此时其他线程 2 的查询就会被堵塞,随后该线程 1 就进行查询数据库和缓存更新,更新完成后释放锁,线程 2 也可以查询到数据了。能保持 redis 和 mysql 的强一致性,但是性能差(阻塞其他线程)
逻辑过期
高可用,性能优,但是不能保证数据强一致性
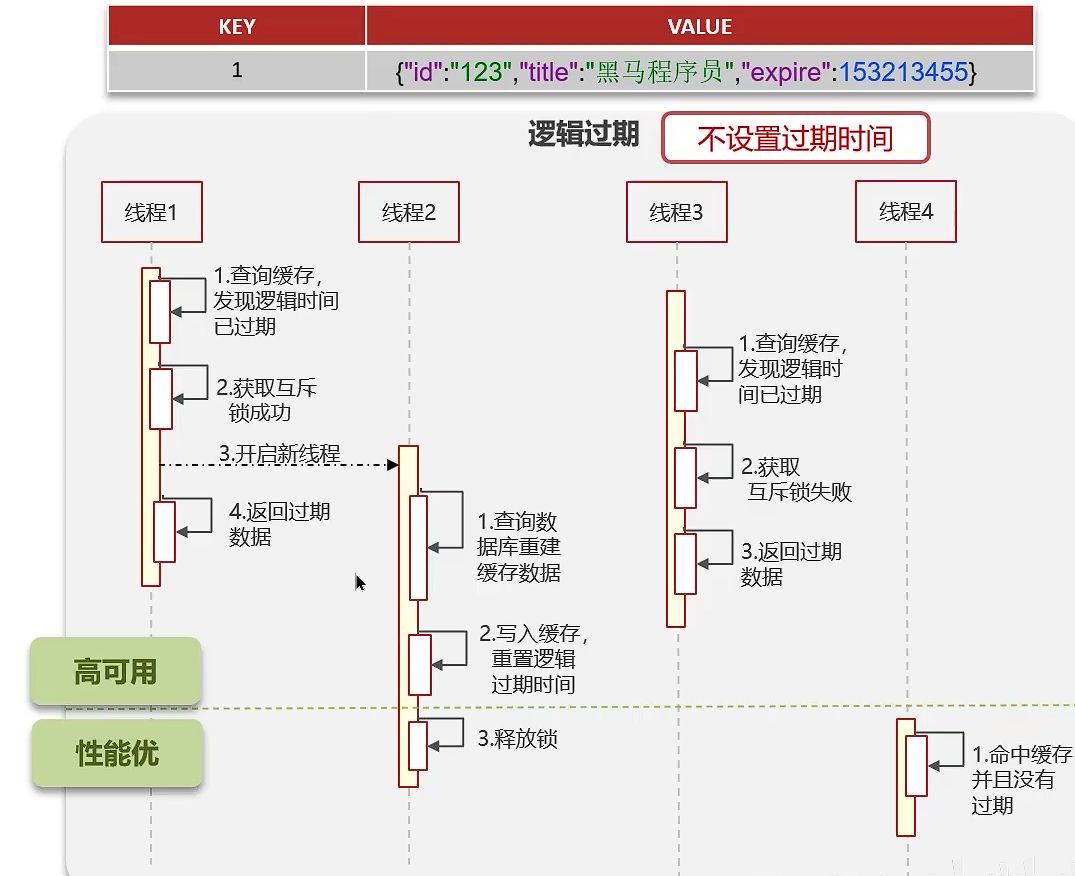
如图,线程 1 在查询时发现缓存过期后会先获取锁,然后新建一个子线程进行数据库查询和缓存更新 等子线程完成后就释放锁,在得到锁的过程中其他线程如果要查询该缓存,发现过期后,也想进行更新,但是发现被锁了,就直接返回过期的缓存数据。只有当锁释放后,其他线程才能获得最新数据。
由此可见,不会阻塞其他线程的查询,所以效率高,但会导致查询的数据不一定是最新的,即非时效性。
缓存雪崩
定义:
当一段时间内 (同一时刻)有大量 key 同时失效,就会导致大量数据查询请求抓发到数据库进行查询,可能会导致数据库崩溃。
解决方法 :
给每个 key 设置不同的过期时间,防止大量 key 同时失效。
如:给每个 key 的过期时间 TTL 加上一个随机值
搭建 Redis 集群,提高服务可用性 (涉及到[[集群模式]] 和[[哨兵]])
- #todo 写 Redis 集群和哨兵
给缓存业务添加限流策略
Spring cloud gateway 或 nginx 等
添加多级缓存
一级缓存用 Caffeine 或 Guava



